



本ブログは、これからデータ分析を学ぼうとしている方向けに、最短で動かす方法をシェアすることを目的としています。従って、動くコードに主眼をおいています。
今回扱うテーマは時刻データを含む観測データの取り扱いです。
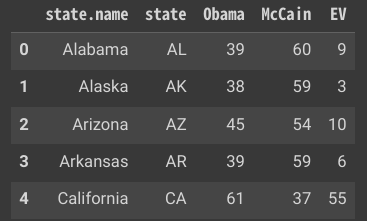
データ分析を進めるなかで、「カテゴリ別の直近の観測データ」を抽出したいときがあると思います。ここでは、「社会科学のためのデータ分析」で用いられているオープンデータセットを例に説明します。
| 変数 | 説明 |
|---|---|
| state | 州の略称 |
| state.name | 省略されていない州名 |
| Obama | オバマの得票率(パーセンテージ) |
| McCain | マケインの得票率(パーセンテージ) |
| EV | その州の選挙人票の数 |
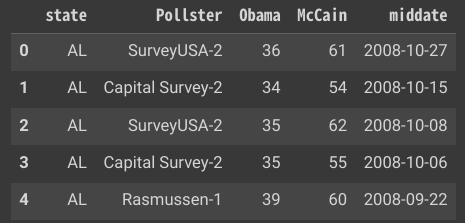
| 変数 | 説明 |
|---|---|
| state | 世論調査の行われた州の略称 |
| Obama | 予測されたオバマの支持率(パーセンテージ) |
| McCain | 予測されたマケインの支持率(パーセンテージ) |
| Pollster | 世論調査を行った組織の名前 |
| middate | 世論調査が行われた期間の中間日 |
下記ヒストグラム(図1)は、オープンデータセットを元に、2008年のアメリカ大統領選の世論調査と実際の選挙結果の差異の分布を示しています。
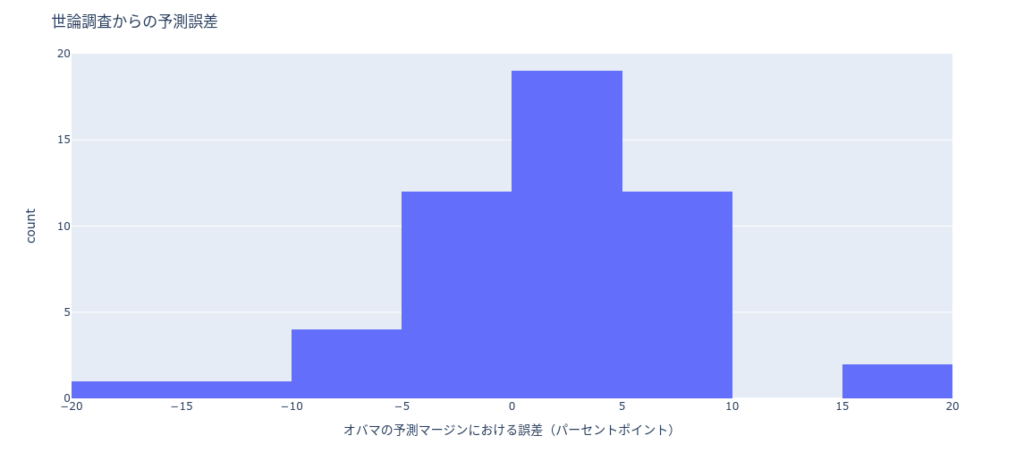
このグラフから下記が読み取れます。
ヒストグラムを見ると、世論調査からの予測誤差が州によって大きく異なることがわかる。しかし、ほとんど誤差は比較的小さく、大きな誤差ほど起こりにくく、0を中心とした釣り鐘形(hell-shaped)となっている。
「社会科学のためのデータ分析入門(上)」4予測 4.1 「選挙結果の予測」
元のデータセットから上記グラフを出力するために実施している処理は下記になります。
- 日付カラム(middate)の設定値と基準日(選挙日=11/4)との差異を算出する
- カテゴリ(state)ごとに基準日との差異が最小のレコードを抽出する
- 抽出したレコードの世論調査の結果(※ここでは Obama-McCain)の平均を算出する
上記処理は、データセット2(世論調査)を使用していますが、この結果とデータセット1(選挙結果)をマージすることで、アメリカ大統領選挙の世論調査の州ごとの予測誤差が取得出来ます。
本記事では、Pandas の DataFrame をインプット情報として カテゴリ別の直近の観測データを抽出する方法(動くコード)を紹介します。
カテゴリ別の直近の観測データを抽出する
サンプルコード(Colab で利用可能)
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
事前準備
import pandas as pd
# 2008年アメリカ大統領選挙データ
df_pres08 = pd.read_csv("https://raw.githubusercontent.com/kosukeimai/qss/master/PREDICTION/pres08.csv")
df_pres08.head()
# 2008年アメリカ大統領選挙世論調査データ
df_polls08 = pd.read_csv("https://raw.githubusercontent.com/kosukeimai/qss/master/PREDICTION/polls08.csv")
df_polls08.head()
# オバマの得票率からマケインの得票率を引いた差(マージン)をパーセントポイントで表したmarginという変数を両方のデータセットに作成する
df_pres08["margin"] = df_pres08["Obama"] - df_pres08["McCain"]
df_polls08["margin"] = df_polls08["Obama"] - df_polls08["McCain"]
# オバマの得票率からマケインの得票率を引いた差(マージン)をパーセントポイントで表したmarginという変数を両方のデータセットに作成する
df_pres08["margin"] = df_pres08["Obama"] - df_pres08["McCain"]
df_polls08["margin"] = df_polls08["Obama"] - df_polls08["McCain"]日付カラムの設定値と基準日との差異を算出する
import datetime
# middateを日付型に変換
df_polls08["middate2Date"] = pd.to_datetime(df_polls08["middate"])
# 選挙日までの日数を計算
df_polls08["DateToElection"] = datetime.datetime(year=2008, month=11, day=4) - pd.to_datetime(df_polls08["middate2Date"])
df_polls08["DateToElection"] = df_polls08["DateToElection"].dt.daysカテゴリごとに基準日との差異が最小のレコードを抽出する
from statistics import mean as st_Mean
import numpy as np
for i, _state in enumerate(df_polls08["state"].unique()):
# 直近の世論調査の平均を算出する
_pred = st_Mean(
df_polls08[(df_polls08["state"] == _state) & (df_polls08["DateToElection"]==df_polls08[df_polls08["state"] == _state]["DateToElection"].min())]["margin"]
)
if i == 0:
np_temp = np.array([np.array([_state, _pred])])
else:
np_temp = np.append(np_temp, np.array([np.array([_state, _pred])]), axis=0)
df_temp = pd.DataFrame(np_temp, columns=["state","pred"])可視化例
import plotly.express as px
df_pres08_add_pred = pd.merge(df_pres08, df_temp, on='state', how='inner')
df_pres08_add_pred["pred"] = df_pres08_add_pred["pred"].astype(float)
df_pres08_add_pred["errors"] = df_pres08_add_pred["margin"] - df_pres08_add_pred["pred"]
fig = px.histogram(df_pres08_add_pred, x="errors")
fig.update_layout(title='世論調査からの予測誤差')
fig.update_xaxes(title_text="オバマの予測マージンにおける誤差(パーセントポイント)")
fig.show()
まとめ
本記事では、Pandas の DataFrame をインプット情報として カテゴリ別の直近の観測データを抽出する方法を紹介しました。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。
また、データのビジュアル化に興味のある方は合わせて下記もご参考ください。
また、データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。