



本ブログは、これからデータ分析を学ぼうとしている方向けに、最短で動かす方法をシェアすることを目的としています。従って、動くコードに主眼をおいています。
今回扱うテーマはクラスタリングです。
データ分析を進めるなかで、データ内の似たような特徴をもつ隠れたグループを発見したいときがあると思います。
散布図でビジュアル化することで、データの特徴は可視化出来ますが、元データが持つ情報以上の可視化は出来ません。
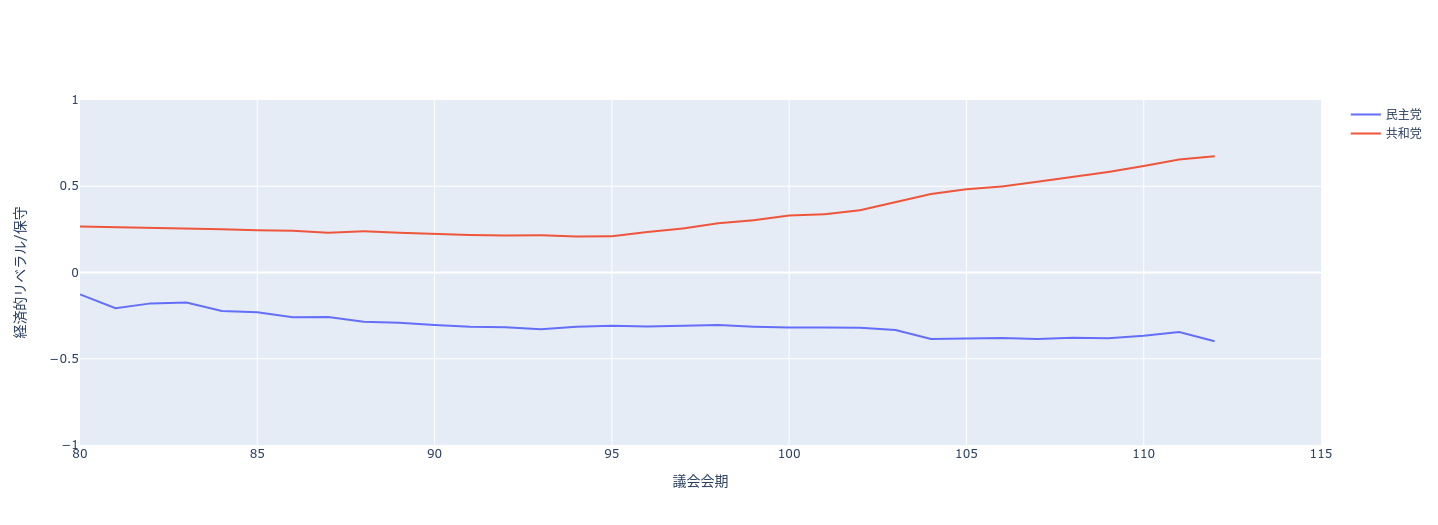
ここでは、「社会科学のためのデータ分析」で用いられているオープンデータセットを例に説明します。下記散布図(図1)は、政治的分極化のデータセット(詳細は本編を参照下さい)を元に可視化しています。データセットの「経済的リベラル/保守」と「人種的リベラル/保守」でプロットし、「政党情報」で色分けしています。(赤:民主党、青:共和党)
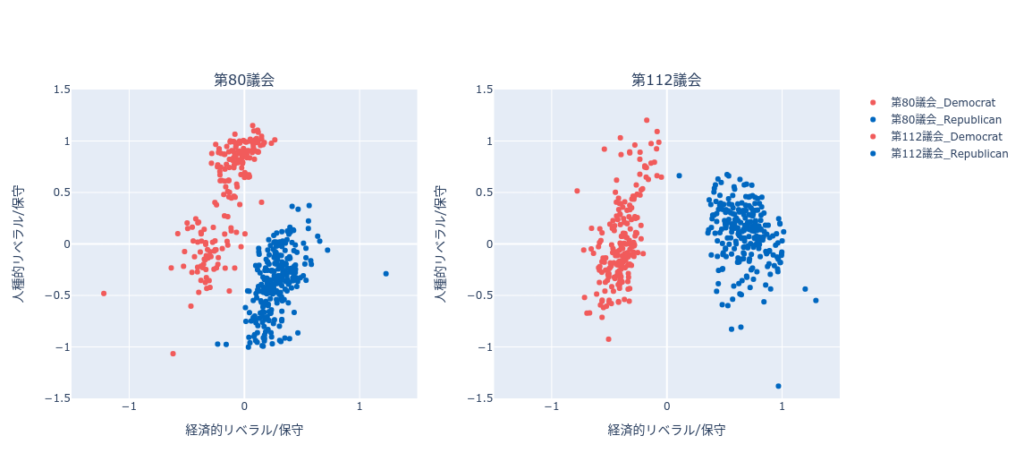
元データが持つ情報で色分け
散布図によりデータの特徴は可視化出来ますが、隠れたグループの発見はできません。
クラスタリングをするとどうなるでしょうか?
下記散布図(図2-1, 図2-2)では、同じデータを使用していますが、色分けの際に政党情報ではなく、「経済的リベラル/保守」と「人種的リベラル/保守」を k-means というクラスタリングアルゴリズムでクラスター化した結果で色分けしています。下記例の場合は、4つのクラスター化しています。(クラスター_0〜4)また、”x” は各クラスターの重心を表しています。(重心については、k-meansの詳細をご確認ください。)
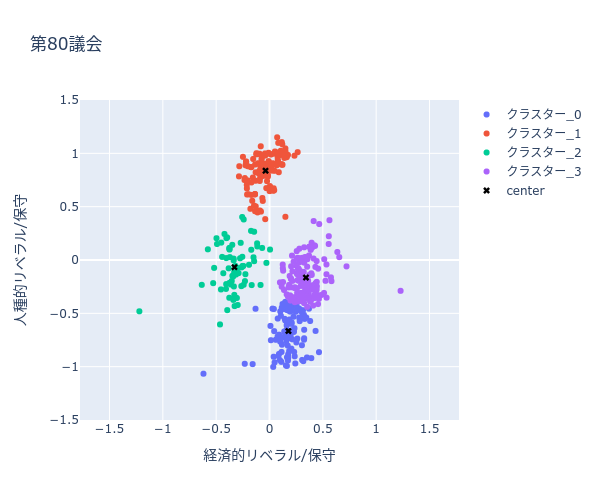
k-meansでクラスタリングした結果を可視化(第80議会)
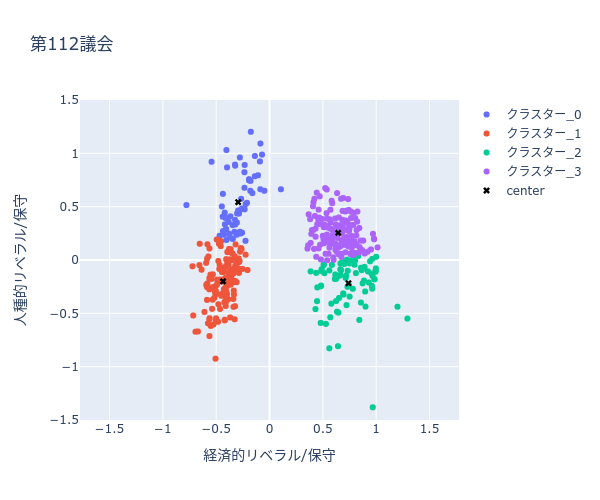
k-meansでクラスタリングした結果を可視化(第112議会)
クラスタリングにより下記が読み取れます
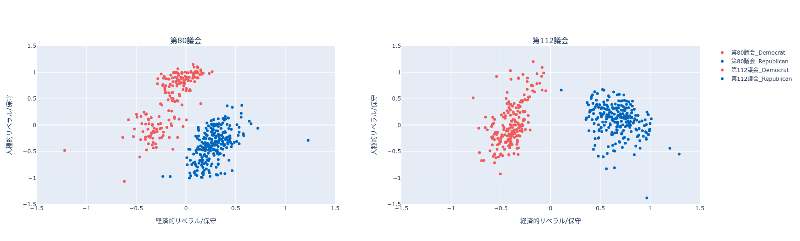
分析結果から、4クラスターモデルでは、民主党が2クラスターに、共和党も2クラスターに分かれることがわかる。政党ごとにみると、第80議会の民主党が2つのクラスター間の違いが最も顕著である。どちらの政党でも、政党内の違いは人種的次元に沿って表れている。対象的に、経済的次元は、政党間の違いを支配している。
「社会科学のためのデータ分析入門(上)」3測定 3.7 「クラスター化」
このように、クラスタリングすることでデータ内の似たような特徴をもつ隠れたグループが発見できます。グループの発見によりデータに対する下記インサイトが得られます。
- 政党内の違いは人種的次元に沿って表れている
- 経済的次元は、政党間の違いを支配している
本記事では、Pandas の DataFrame をインプット情報として sklearn を使用して k-means でクラスタリングして plotly で可視化する方法(動くコード)を紹介します。
k-meansによるクラスタリング結果を出力する
サンプルコード(Colab で利用可能)
基本メソッド
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
【参考】k-means の実行には sklearn ライブラリーを活用します。
import pandas as pd
import numpy as np
import plotly.graph_objects as go
from sklearn.cluster import KMeans
def _clusterplot_by_kmeans(_df, _x, _y, _n_clusters, _title, _xtitle, _ytitle, _crosstab):
_df = _df.reset_index(drop=True)
print(f"・{_n_clusters}個にクラスタ化します")
kmeans_model = KMeans(n_clusters=_n_clusters, random_state=10).fit(_df[[_x, _y]])
df_labels = pd.DataFrame(kmeans_model.labels_, columns=["labels"])
df_k_means = pd.concat([_df, df_labels], axis=1)
print(f"・クラスタ結果と{_crosstab}カラムを比較します")
print(pd.crosstab(df_k_means[_crosstab].fillna('<NaN>'), df_k_means['labels'].fillna('<NaN>'), margins=True))
print("")
df_cluster_centers = pd.DataFrame(kmeans_model.cluster_centers_, columns=["x","y"])
print("・クラスタ結果を散布図にプロットします")
for _clusters in range(_n_clusters):
if _clusters == 0:
fig = go.Figure(
data= go.Scatter(
x=df_k_means[df_k_means["labels"]==_clusters][_x],
y=df_k_means[df_k_means["labels"]==_clusters][_y],
mode='markers',
name=f"クラスター_{_clusters}"
)
)
else:
fig.add_trace(
go.Scatter(
x=df_k_means[df_k_means["labels"]==_clusters][_x],
y=df_k_means[df_k_means["labels"]==_clusters][_y],
mode='markers',
name=f"クラスター_{_clusters}"
)
)
fig.add_trace(
go.Scatter(
x=df_cluster_centers["x"],
y=df_cluster_centers["y"],
mode='markers',
marker_symbol="x",
name="center",
marker_color='#000000'
)
)
fig.update_layout(
title={
'text': _title
}
)
fig.update_xaxes(title_text=_xtitle)
fig.update_yaxes(title_text=_ytitle)
return fig, df_k_means使用例
「社会科学のためのデータ分析」で用いられているオープンデータセットでの使用例を紹介します。
使用例:政治的分極化のデータセット
基本メソッド実行後に、今回使用するデータ専用に目盛りやサイズを調整する処理を実行するメソッドを定義します
def _plot_example(_df, _congress, _n_clusters):
fig, df_k_means = _clusterplot_by_kmeans(
_df[_df["congress"]==_congress],
"dwnom1",
"dwnom2",
_n_clusters,
f"第{_congress}議会",
"経済的リベラル/保守",
"人種的リベラル/保守",
"party"
)
fig.update_layout(
width=600,
height=500
)
fig.update_xaxes(
range=[-1.5, 1.5],
dtick = 0.5
)
fig.update_yaxes(
range=[-1.5, 1.5],
scaleanchor = "x",
scaleratio = 1,
dtick = 0.5
)
fig.show()これで準備が終わりました。
まずはじめに、サンプルデータを取得します。
# web上のcsvファイルを取得
df_congress = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/MEASUREMENT/congress.csv')
df_congress.head()次に、メソッドを実行します。
# 第80議会のデータをk-meansを使用して4種類にクラスタリングして可視化
_plot_example(df_congress[df_congress["party"].isin(["Democrat","Republican"])], 80,4)クラスタリング結果(図3-1)が出力されます。

引数を変えてメソッドを実行します。
# 第112議会のデータをk-meansを使用して4種類にクラスタリングして可視化
_plot_example(df_congress[df_congress["party"].isin(["Democrat","Republican"])], 112,4)クラスタリング結果(図3-2)が出力されます。

まとめ
本記事では、Pandas の DataFrame をインプット情報として sklearn を使用して k-means でクラスタリングして plotly で可視化する方法を紹介しました。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。
また、データのビジュアル化に興味のある方は合わせて下記もご参考ください。
また、データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。