



今回のテーマは、重要なモノを浮き彫りにする方法です。
本記事では、Pandas の DataFrame をインプット情報として plotly でイケてるパレート図を出力する方法を紹介します。
本記事を最後まで読むと1行でパレート図を出力する方法が解ります。
目次
パレート図を出力するサンプルコード(Colab で利用可能)
コード
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
import pandas as pd
from plotly.subplots import make_subplots
import plotly.graph_objects as go
def pyPareto(_df:pd.core.frame.DataFrame, _colNm):
df_temp = pd.concat(
[
_df.rename(columns={_colNm: _colNm + "_counts"})[_colNm + "_counts"].value_counts(ascending=False),
_df.rename(columns={_colNm: _colNm + "_normalize"})[_colNm + "_normalize"].value_counts(ascending=False, normalize=True),
_df.rename(columns={_colNm: _colNm + "_cumsum"})[_colNm + "_cumsum"].value_counts(ascending=False, normalize=True).cumsum()
], axis=1)
df_temp[_colNm] = df_temp.index
df_temp[_colNm] = '"' + df_temp[_colNm].astype('str') + '"'
df_temp["text"] = "normalize:" + (df_temp[_colNm + "_normalize"]*100).astype(str).str[:5] + "%" + " ,cumsum:" + (df_temp[_colNm + "_cumsum"]*100).astype(str).str[:5] + "%"
fig=make_subplots(specs=[[{"secondary_y":True}]])
fig.add_trace(
go.Bar(
x=df_temp[_colNm],
y=df_temp[_colNm + "_counts"],
name="counts"
),
secondary_y=False)
fig.add_trace(
go.Scatter(
x=df_temp[_colNm],
y=df_temp[_colNm + "_cumsum"],
name="cumsum",
mode='lines',
text=df_temp["text"],
hoverinfo='text'
),
secondary_y=True)
fig.update_yaxes(range=[0, 1], secondary_y=True)
fig.update_layout(
title_text=_colNm + " pareto chart",
hovermode='x unified'
)
fig.show()
return 使用例
「社会科学のためのデータ分析入門」で用いられているオープンデータセットでの使用例を紹介します。
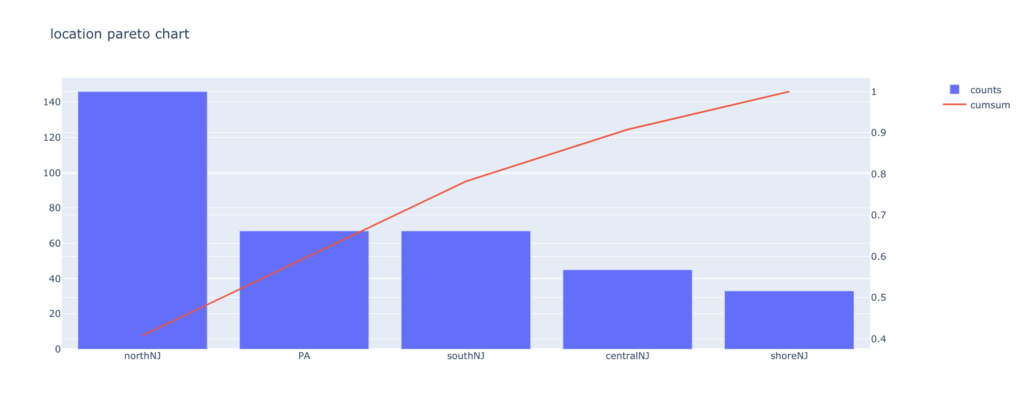
使用例①:最低賃金と失業率の調査のデータセット
取得したデータの「location」カラムのパレート図を出力します。
df_minwage = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/CAUSALITY/minwage.csv')
pyPareto(df_minwage, "location")
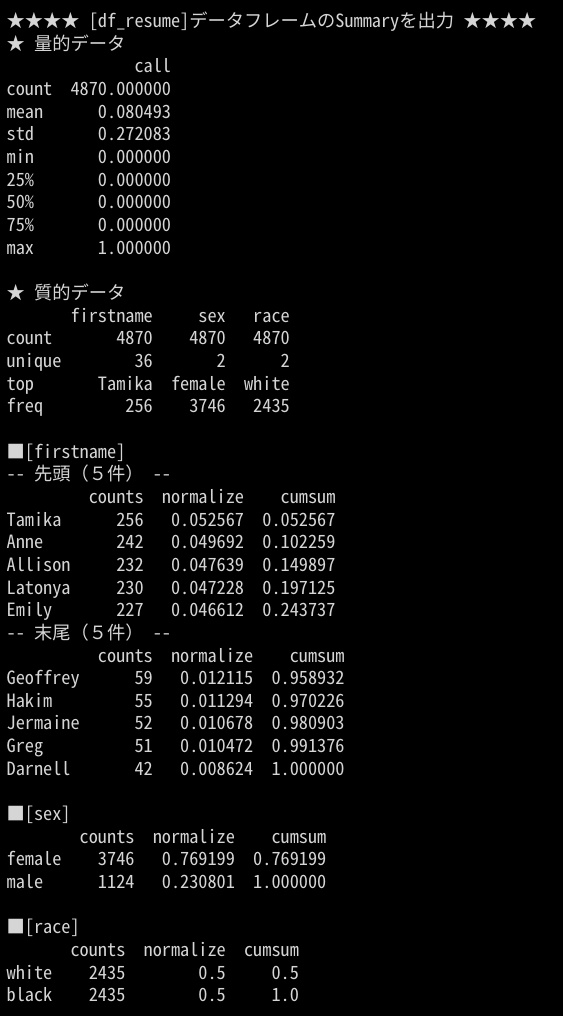
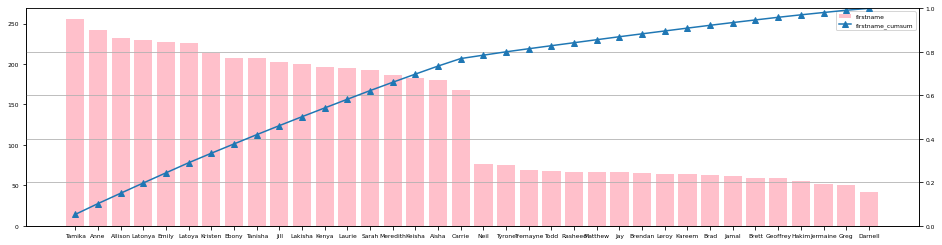
使用例②:労働市場における人種差別の調査のデータセット
取得したデータの「firstname」カラムのパレート図を出力します。
df_resume = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/CAUSALITY/resume.csv')
pyPareto(df_resume, "firstname")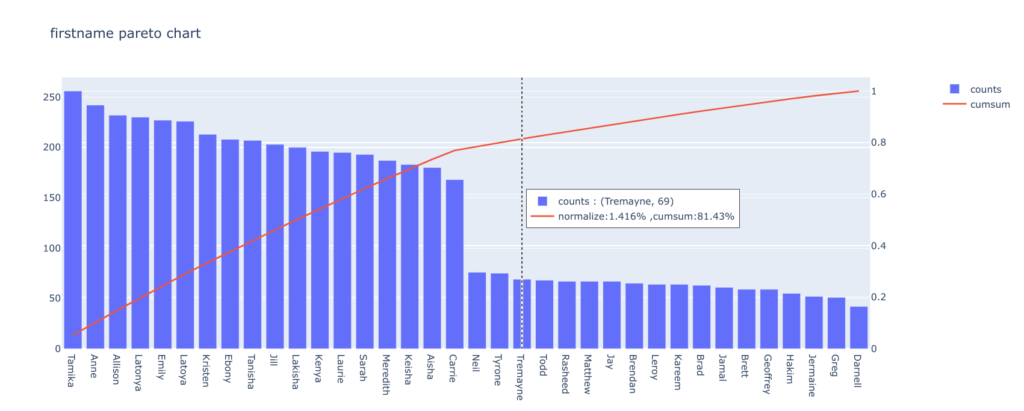
【参考】Plotly によるデータ可視化
Plotly を活用したデータ可視化についてご興味のある方は下記記事をご参考ください。
【参考】Pandasによるデータ確認
Pandas を活用したデータ確認についてご興味のある方は下記記事をご参考ください。
【参考】sklearn+numpy によるモデルの評価
まとめ
本記事では、Pandas の DataFrame をインプット情報として plotly でイケてるパレート図を出力するメソッドを紹介しました。
データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。