



データ分析を進めるなかで、2つの変数の分布全体を比較する必要に迫られたことはありませんか?
2つのヒストグラムを並べて表示すれば比較可能ですが、ざっくりしすぎていて分析には向きません。
そこで、2つの確率分布の分位数をプロットして比較するQ-Qプロットを活用します。
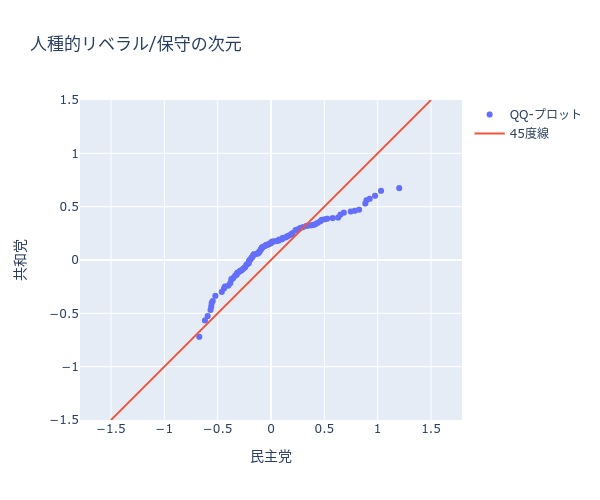
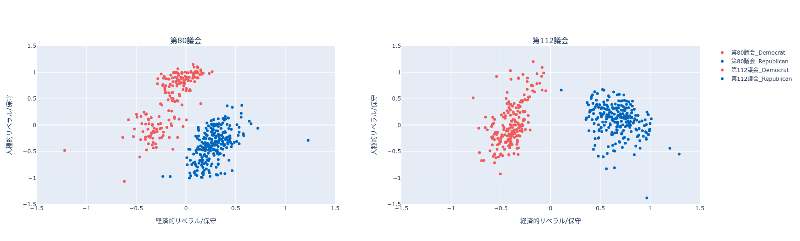
このQ-Qプロットは、横軸が民主党の、縦軸が共和党の人種に関する次元を示す。下位分位数を表す点が45度線を超えていることは、リベラルな共和党員のほうが、リベラルな民主党員よりも保守的であることを示している。これは、民主党よりも共和党のほうが、対応する分位数の値が大きい(より保守的である)ことによる。対照的に、上位分位数は45度線より下に位置している。つまり、最も高い分位数、すなわち、最も保守的な政治家は、民主党員のほうが共和党員よりも保守的となっている。したがって、保守的な民主党員は、保守的な共和党員よりも保守的である。仮に、上位分位数がすべて45度線よりも上に位置しているのであれば、保守的な共和党員のほうが保守的な民主党員よりも保守的だということになる。最後に、各点をつなぐ線は45度線よりも平坦であり、イデオロギー位置の分布は、共和党よりも民主党のほうが広く散らばっていることを示している。
「社会科学のためのデータ分析入門(上)」3測定 3.6.3 「Q-Qプロット」
本記事では、Pandas の DataFrame をインプット情報として plotly でQ-Qプロットを出力する方法を紹介します。
Q-Qプロットを出力するサンプルコード(Colab で利用可能)
コード
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
import pandas as pd
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import numpy as np
def qq_np2df(_np1:np.array, _np2:np.array):
def np_qq_percentile(_np_1:np.array, _np_2:np.array, _percentile):
return np.array([np.array([_percentile, np.percentile(_np_1, _percentile), np.percentile(_np_2, _percentile)])])
for i in range(100):
if i == 0:
np_temp = np_qq_percentile(_np1, _np2, i+1)
else:
np_temp = np.append(np_temp, np_qq_percentile(_np1, _np2, i+1), axis=0)
df_temp = pd.DataFrame(np_temp)
return df_temp
def qq_plot(_np1:np.array, _np2:np.array, _xaxes_range, _yaxes_range, _dtick, _title, _xtitle, _ytitle):
_df = qq_np2df(_np1, _np2)
_qq_df = pd.concat([pd.DataFrame(data=_xaxes_range, columns=['x']),pd.DataFrame(data=_yaxes_range, columns=['y'])], axis=1).head()
fig = go.Figure(
data= go.Scatter(
x=_df[1],
y=_df[2],
mode='markers',
name="QQ-プロット"
)
)
fig.update_layout(
title={
'text': _title
},
width=600,
height=500
)
fig.add_trace(
go.Scatter(
x=_qq_df["x"],
y=_qq_df["y"],
mode='lines',
name="45度線"
)
)
fig.update_yaxes(
range=_yaxes_range,
scaleanchor = "x",
scaleratio = 1,
dtick = _dtick,
title_text=_ytitle
)
fig.update_xaxes(
range=_xaxes_range,
dtick = _dtick,
title_text=_xtitle
)
fig.show()使用例
「社会科学のためのデータ分析」で用いられているオープンデータセットでの使用例を紹介します。
使用例:政治的分極化のデータセット
取得したデータを
# 政治的分極化のデータセットを取得
df_congress = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/MEASUREMENT/congress.csv')
# 取得したデータから必要データを抽出して numpy に変換
np_dem_dwnom2 = df_congress[(df_congress["congress"]==112)&(df_congress["party"]=="Democrat")][["dwnom2"]].to_numpy()
np_rep_dwnom2 = df_congress[(df_congress["congress"]==112)&(df_congress["party"]=="Republican")][["dwnom2"]].to_numpy()
_xaxes_range = [-1.5, 1.5]
_yaxes_range = [-1.5, 1.5]
_dtic = 0.5
qq_plot(np_dem_dwnom2, np_rep_dwnom2, _xaxes_range, _yaxes_range, _dtic, "人種的リベラル/保守の次元", "民主党", "共和党")
まとめ
本記事では、Pandas の DataFrame をインプット情報として plotly でQ-Qプロットを出力するメソッドを紹介しました。
データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。
合わせて下記もご参考ください。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。