



Pandas では少しの工夫で特徴を捉えるためのデータを出力することが出来ます。
しかし、テキストデータだけではどうもイメージがし辛いと思います。
本記事では、Pandas の DataFrame をインプット情報として plotly で中央値の時系列の推移を比較する方法を紹介します。
中央値の推移の比較のサンプルコード(Colab で利用可能)
サンプルデータセット
「社会科学のためのデータ分析」で用いられているオープンデータセットでの使用例を紹介します。
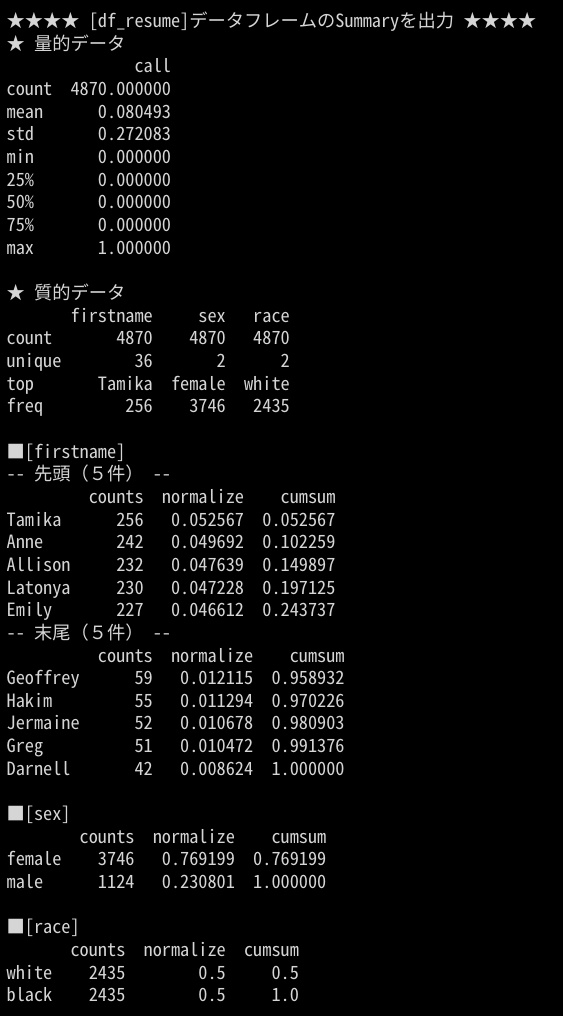
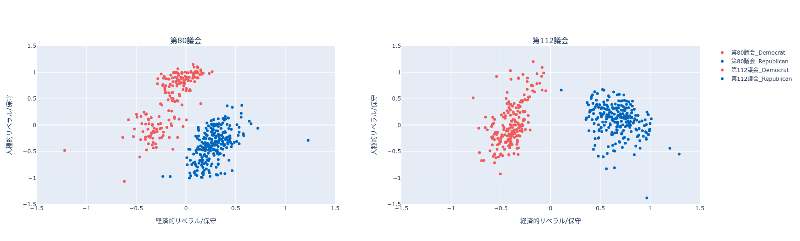
出力イメージ
DataFrame の中央値の時系列の推移を出力することが出来ます。
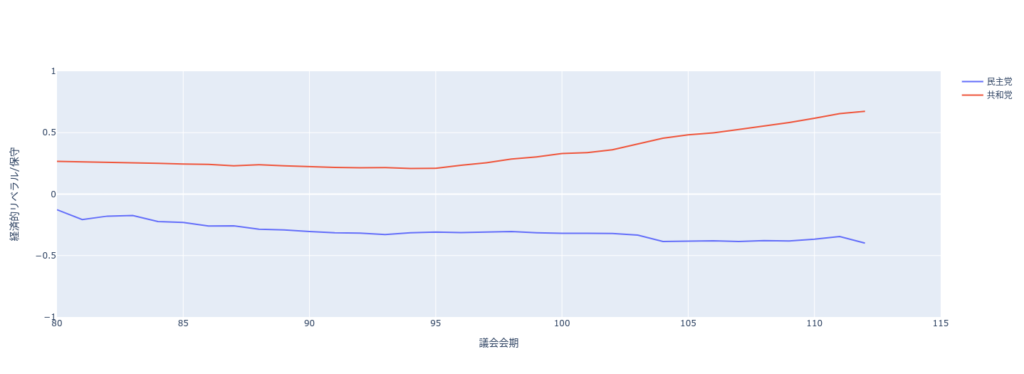
この図から、2大政党制のイデオロギーの中心は時間とともに離れていっていることが明白である。近年、民主党はよりリベラルになり、共和党はますます保守化している。多くの研究者がこの現象を政治的分極化(political polarization)と呼んでいる
「社会科学のためのデータ分析入門(上)」3測定 3.6 「2変量関係の要約」
コード
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
import pandas as pd
from plotly.subplots import make_subplots
import plotly.graph_objects as go
def congress_go_scatter_median_lines(_df, _party, _x, _y, _name):
# pivot_table を使用して、_x に指定したカラム(質的データ)の設定値毎に、 _y に指定したカラム(量的データ)の値の中央値を算出
# plotly で可視化するために転置(行と列の入れ替え)を実施
df_temp = pd.pivot_table(_df[_df["party"]==_party], columns=_x, values=_y, aggfunc="median").T
# plotly で可視化するためにインデックスの値をカラムに設定
df_temp[_x]=df_temp.index
# 違いをわかりやすくするために、mode には "lines" を指定して線を表示
return go.Scatter(
x=df_temp[_x],
y=df_temp[_y],
mode='lines',
name=_name
)
df_congress = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/MEASUREMENT/congress.csv')
fig = go.Figure(data=congress_go_scatter_median_lines(df_congress, "Democrat", 'congress','dwnom1', "民主党"))
fig.add_trace(congress_go_scatter_median_lines(df_congress,"Republican", 'congress','dwnom1', "共和党"))
fig.update_xaxes(title_text="議会会期", range=[80, 115])
fig.update_yaxes(title_text="経済的リベラル/保守", range=[-1, 1])
fig.show()まとめ
本記事では、Pandas の DataFrame をインプット情報として plotly で中央値の時系列の推移を比較するメソッドを紹介しました。
データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。
合わせて下記もご参考ください。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。