



Pandas では describe() で基本統計量が出力出来ますが、質的データに関してはやや情報が不足していることありませんか?(R言語のSummary()関数のようにもう少しだけ情報が出力されれば・・)
本記事では、describe() を補完する形で、
質的データの変数毎に各値ごとの「件数・割合・割合の累積和」を出力するメソッドを紹介します。
本記事を最後まで読むと1行でデータの特徴を出力する方法が解ります。
データの特徴(基本統計量や頻度)を出力するサンプルコード
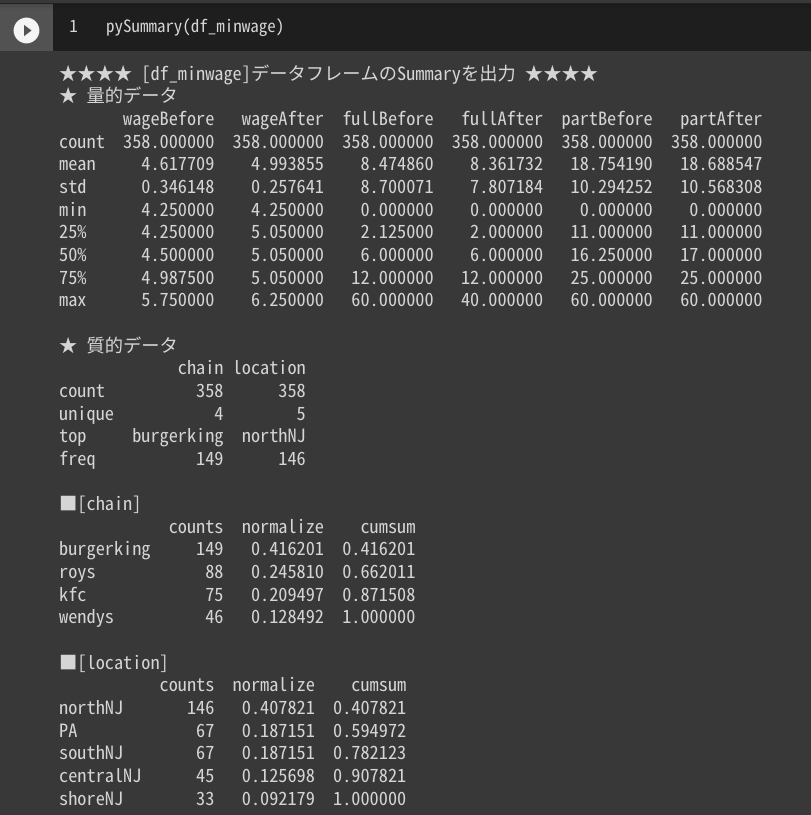
出力イメージ
量的データと質的データが混在する DataFrame に対して、量的データは基本統計量を、質的データは件数・割合・割合の累積和を出力することが出来ます。
コード
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
import pandas as pd
def pySummary(_df:pd.core.frame.DataFrame):
vnames = [name for name in globals() if globals()[name] is _df]
if len(vnames) > 0:
print(f"★★★★ [{vnames[0]}]データフレームのSummaryを出力 ★★★★")
try:
print("★ 量的データ")
print(_df.describe())
print("")
except:
print("※数値変数なし")
print("")
try:
print("★ 質的データ")
print(_df.describe(exclude="number"))
print("")
# 質的データのみを対象
for i in _df.describe(exclude="number").columns:
print(f"■[{i}]")
if len(_df[i].value_counts()) > 10:
# データ件数が多い場合、上位5件と下位5件のみ表示
print("-- 先頭(5件) --")
print(pd.concat(
[
_df.rename(columns={i: "counts"})["counts"].value_counts(ascending=False).head(5),
_df.rename(columns={i: "normalize"})["normalize"].value_counts(ascending=False, normalize=True).head(5),
_df.rename(columns={i: "cumsum"})["cumsum"].value_counts(ascending=False, normalize=True).cumsum().head(5)
], axis=1)
)
print("-- 末尾(5件) --")
print(pd.concat(
[
_df.rename(columns={i: "counts"})["counts"].value_counts(ascending=False).tail(5),
_df.rename(columns={i: "normalize"})["normalize"].value_counts(ascending=False, normalize=True).tail(5),
_df.rename(columns={i: "cumsum"})["cumsum"].value_counts(ascending=False, normalize=True).cumsum().tail(5)
], axis=1)
)
else:
# データ件数の多い順
print(pd.concat(
[
_df.rename(columns={i: "counts"})["counts"].value_counts(ascending=False),
_df.rename(columns={i: "normalize"})["normalize"].value_counts(ascending=False, normalize=True),
_df.rename(columns={i: "cumsum"})["cumsum"].value_counts(ascending=False, normalize=True).cumsum()
], axis=1)
)
print("")
except:
print('※質的データなし')
print("")
return使用例
「社会科学のためのデータ分析」で用いられているオープンデータセットでの使用例を紹介します。
使用例①:最低賃金と失業率の調査のデータセット
df_minwage = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/CAUSALITY/minwage.csv')
pySummary(df_minwage)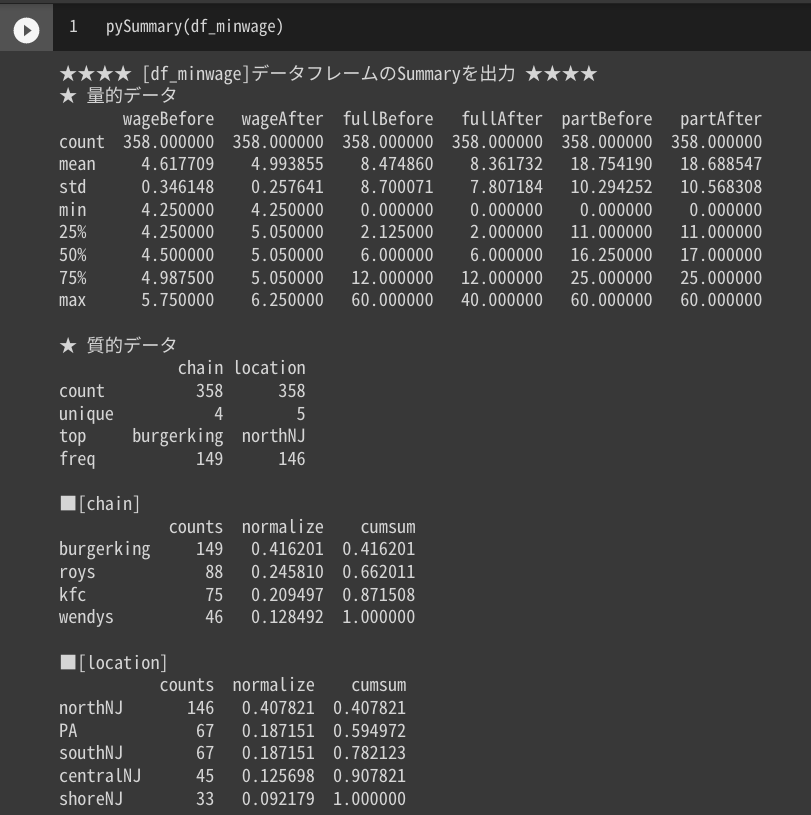
使用例②:労働市場における人種差別の調査のデータセット
df_resume = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/CAUSALITY/resume.csv')
pySummary(df_resume)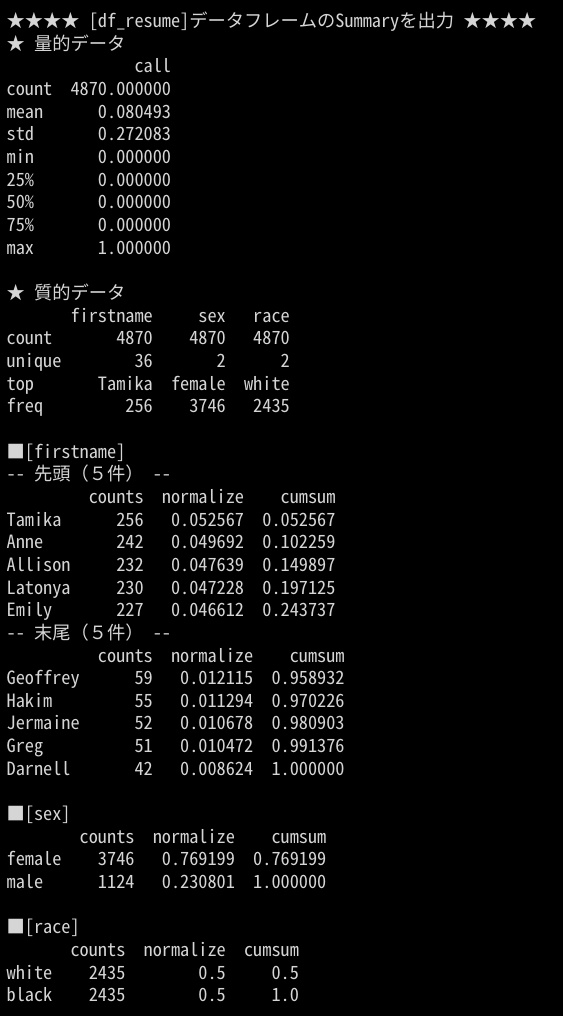
まとめ
本記事では、describe() を補完する形で、質的データの変数毎に各値ごとの「件数・割合・割合の累積和」を出力するメソッドを紹介しました。
一つ一つ丁寧に確認したい方は下記記事をご覧ください。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。