



近年、経済学・政治学を始めとして統計的手法を用いたデータ分析が社会の実問題に適用されるケースが増加しており、この流れは今後ますます加速していくと予想されます。
これからの社会では、データ分析のリテラシーを高めていくことが重要になります。
データ分析では、データ確認から始めます。
データ確認は以下の手順で進めます。
- データをざっくりと理解する
- 量的データの基本統計量を確認する
- 量的データの分布をヒストグラムで確認する
- 質的データの度数分布を確認する
- 質的データの度数分布をパレート図で確認する
データの分類法の一つとして次がある。
量的データ:数値として表され、さらに比率データ(比例尺度ともいう)と間隔データ(間隔尺度ともいう)に分類される。
「ータサイエンス教本 Pythonで学ぶ統計分析・パターン認識・深層学習・信号処理・時系列データ分析」第2章 データの扱いと可視化
質的データ:定性的に表されるもので、非数値表現となる。このため、何らかの数値が割り当てされる。これはさらにカテゴリーデータ(名義尺度ともいう)と順位データ(順位尺度とものいう)に分類される。
本記事では、「社会科学のためのデータ分析」で使用されている米国のオープンデータセットを使ったサンプルコードを交えてデータ確認の方法を紹介します。
「社会科学のためのデータ分析」では基本的に「R言語」で記述されているため、
Google Colaboratoryから直ぐに使える Python に置き換えて紹介します。
また、書籍には記載がありませんでしたが、ヒストグラムやパレート図でのデータ確認方法も合わせて紹介します。
目次
使用するデータと実行環境
使用するデータ
下記サイトのデータを使用します。
実行環境
Google Colaboratoryで実行することを前提とします。
Step1. データをざっくりと理解する
Pandas を使用してデータを読み込む
import pandas as pd
# web上のcsvファイルを取得
df_resume = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/CAUSALITY/resume.csv')Pandasのhead() を使用してデータの内容(一部)を確認する
df_resume.head()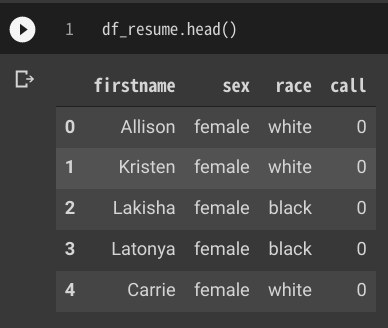
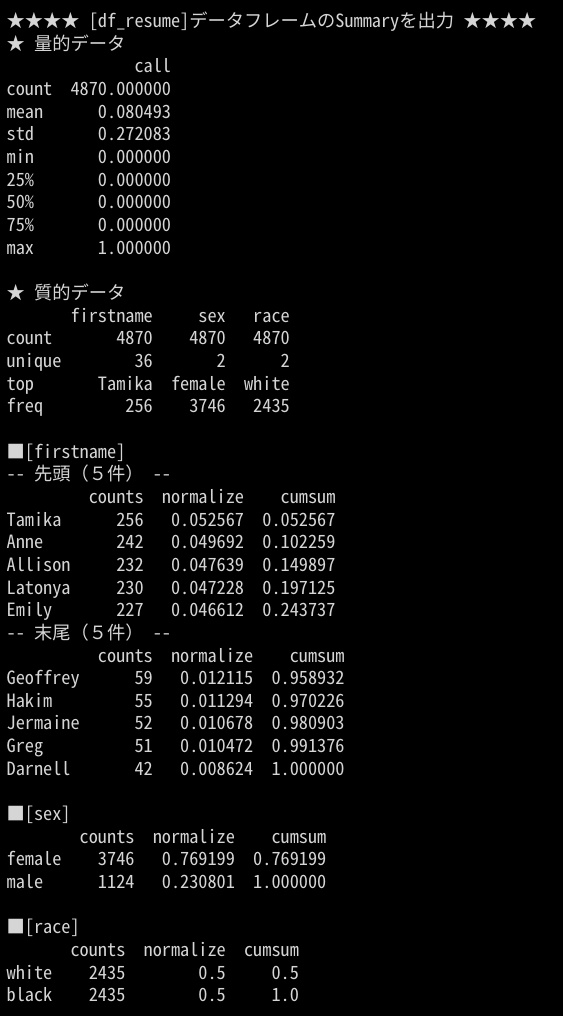
読み込んだデータ(csvファイル)には、「firstname」カラム、「sex」カラム、「race」カラム、「call」カラムがあり、「firstname」カラムにはどうやら人の名前が、「sec」カラムには性別が、「racw」には人種が、「call」には数値情報が格納されていることが読み取れます。
Pandasのinfo() を使用して読み込んだデータの要約情報を確認する
df_resume.info()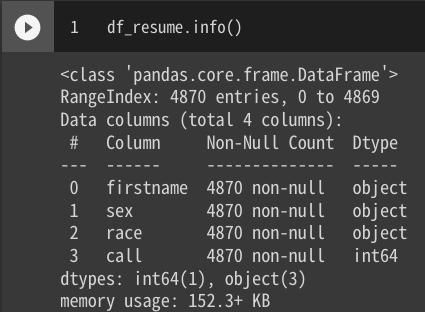
読み込んだデータは、4870行で4カラムあり、firstnameとsexとraceは文字列(つまり質的データが格納)、callには数値(つまり量的データが格納)であることが解ります。
Step2-1. 量的データの基本統計量を確認する
describe() を使用して基本統計量を一括で確認する
量的データの基本統計量の確認は、describe() を使用します。
describe()はデフォルトでは量的データのみを対象に基本統計量(数、平均値、標準偏差、第一四分位数、第二四分位数(中央値)、第三四分位数、最大値)が取得出来ます。
df_resume.describe()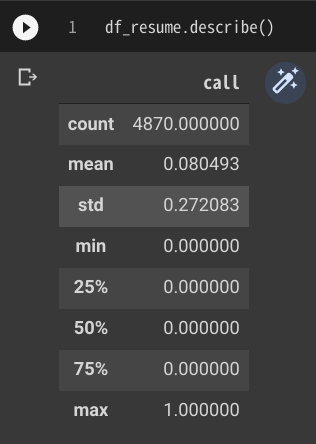
量的データの「call」カラムは、min(最小値)が 0、max(最大値)が 1、第一〜第三四分位数がいずれも 0であることから、0 or 1 が設定されている2値変数であることが解ります。そして、平均値が 0.08 であることからほとんどが 0 であることも解ります。
quantile() を使用してIQR(四分位範囲)と十分位数を取得する
今回使用しているサンプルデータではあまりイメージが沸かないかも知れませんが、quantile() を使用するとIQR(四分位範囲)と十分位数も取得出来ます。
for i in df_resume.describe().columns:
print(f"■[{i}]")
Q1 = df_resume[i].quantile(0.25)
Q3 = df_resume[i].quantile(0.75)
IQR = Q3 - Q1
print(f"IQR(四分位範囲) = {IQR}")
print(f"十分位数 of '{i}'")
print(df_resume[i].quantile(np.arange(0.0, 1.1, 0.1)).transpose())
print("")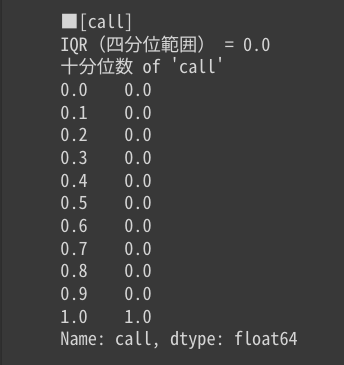
Step2-2. 量的データの分布をヒストグラムで確認する
基本統計量だけではデータのイメージが湧きづらいので、ヒストグラムを出力します。
df_resume["call"].hist(bins=10)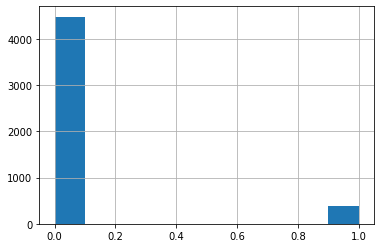
「call」カラムは 0 と 1 に偏っていること、大多数は 0 であることが一目で解ります。
Step3-1. 質的データの度数分布を確認する
Pandasには質的データの度数分布を一括で確認するためのメソッドが用意されていません。
ですので、ここでは少し工夫します。
データフレームに含まれる各質的データの要素の頻度を取得する
# 質的データのみを対象
for i in df_resume.describe(exclude="number").columns:
print(f"■value_counts of '{i}'")
if len(df_resume[i].value_counts()) > 10:
# value_counts() メソッドを使用して件数を取得
# データ件数が多い場合、上位5件と下位5件のみ表示
print("-- 昇順 --")
print(df_resume[i].value_counts(ascending=False).head(5))
print("-- 降順 --")
print(df_resume[i].value_counts(ascending=True).head(5))
else:
# データ件数の多い順
print(df_resume[i].value_counts(ascending=False))
print("")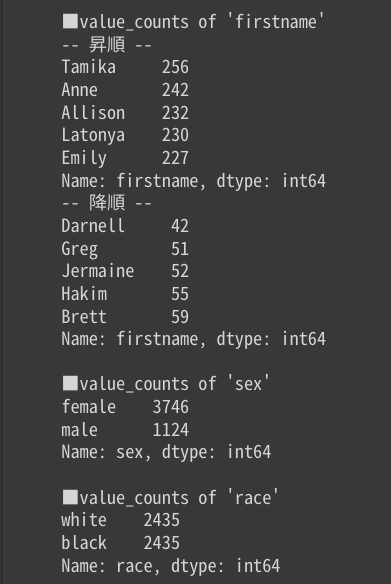
「firstname」カラムには、”Tamika”が最も多く格納されておりその数は256件であり、一方”Darnell”が最も少なく42件であることが解ります。
また、「sex」カラムには”female”の方が多いこと、「race」カラムは”white”と”black”が同数であることが解ります。
データフレームに含まれる各質的データの要素の頻度の割合を取得する
# 質的データのみを対象
for i in df_resume.describe(exclude="number").columns:
print(f"■value_counts of '{i}'")
# 割合[%]を表示
# データ件数が多い場合、上位5件と下位5件のみ表示
if len(df_resume[i].value_counts()) > 10:
print("-- 昇順 --")
print(df_resume[i].value_counts(ascending=False, normalize=True).head(5)*100)
print("-- 降順 --")
print(df_resume[i].value_counts(ascending=True, normalize=True).head(5)*100)
else:
print(df_resume[i].value_counts(normalize=True)*100)
print("")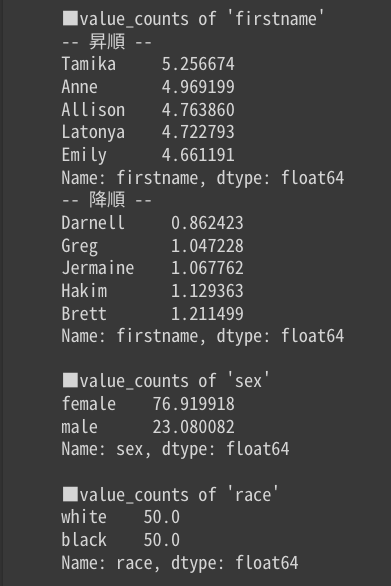
「firstname」カラムに最も多く格納されている”Tamika”の割合が全体の5.2%であることが解ります。
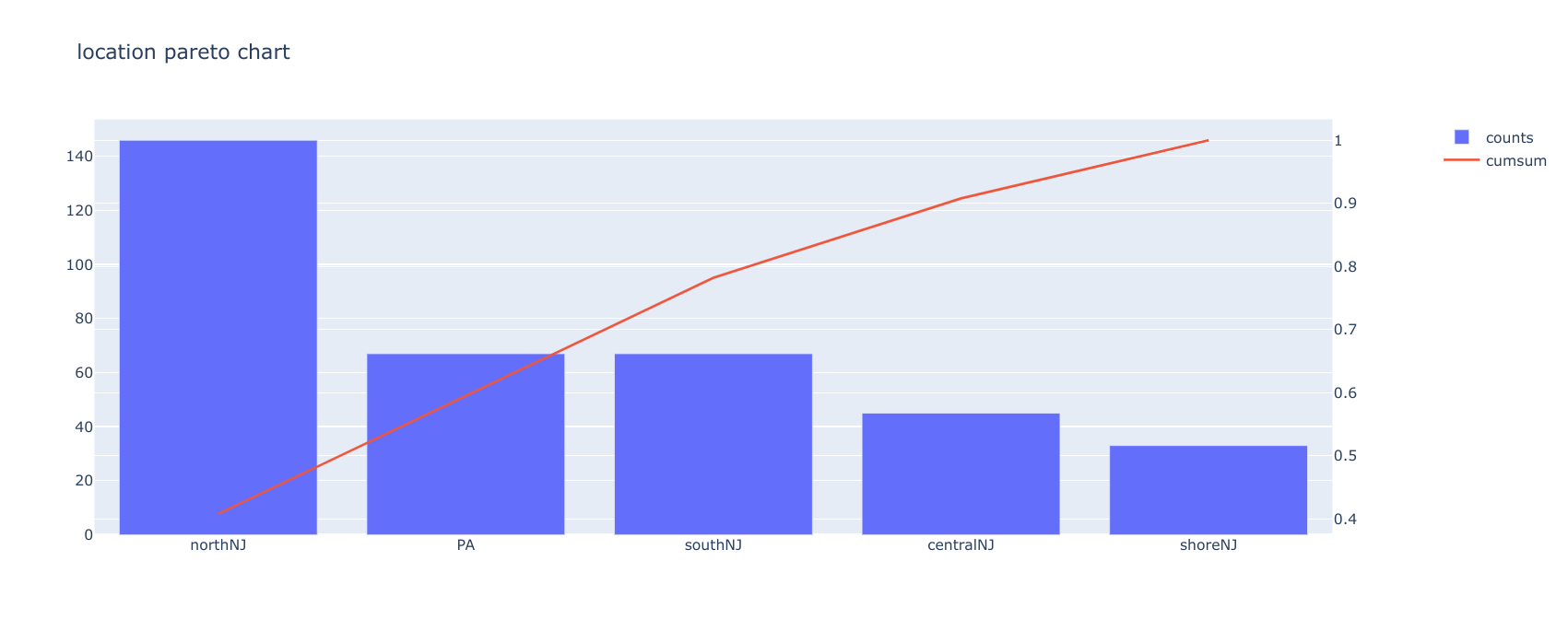
Step3-2. 質的データの度数分布をパレート図で確認する
度数分布を表示しましたが、数値だけでは全体感がつかめないのでパレート図で確認します。
ここではパレート図を出力するメソッド paretoChart() を用意しました。
import matplotlib.pyplot as plt
# パレート図を出力するメソッド
# 第一引数に dataframe
# 第二引数に質的データのカラム名
def paretoChart(_df, _colNm):
df_temp = pd.concat(
[
_df[_colNm].value_counts(),
_df.rename(columns={_colNm: _colNm + "_cumsum"})[_colNm + "_cumsum"].value_counts(normalize=True).cumsum()
], axis=1)
plt.rcParams['font.size'] = 6
# グラフ領域、サブプロットの作成
fig,ax1=plt.subplots(figsize=(16,4))
ax2=plt.twinx(ax1)
ax1.bar(df_temp.index,df_temp[_colNm],label=_colNm,color='pink')
ax2.plot(df_temp.index,df_temp[_colNm + "_cumsum"],label=_colNm + "_cumsum",marker='^')
ax2.set_ylim(0,1)
# gridの設定
plt.grid()
# 凡例の表示
handler1, label1 = ax1.get_legend_handles_labels()
handler2, label2 = ax2.get_legend_handles_labels()
# 凡例をまとめて出力する
ax1.legend(handler1 + handler2, label1 + label2)
paretoChart(df_resume,"firstname")
paretoChart(df_resume,"sex")
paretoChart(df_resume,"race")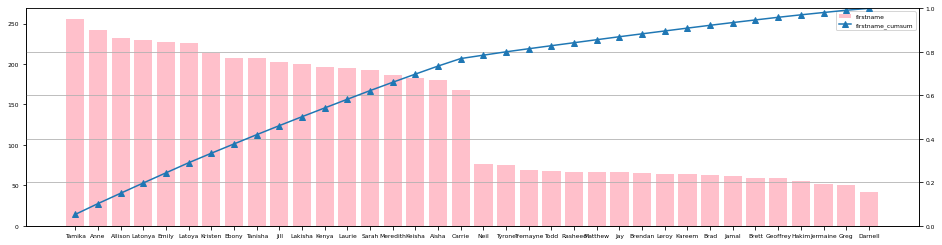
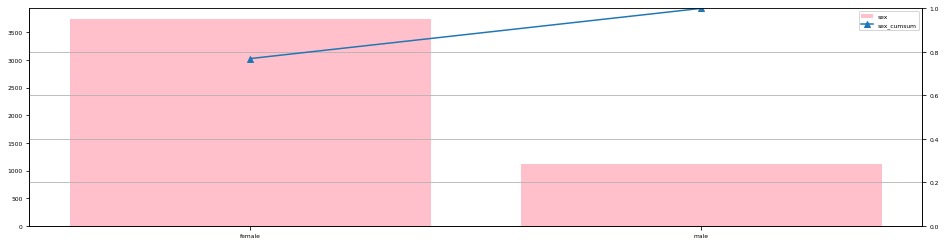
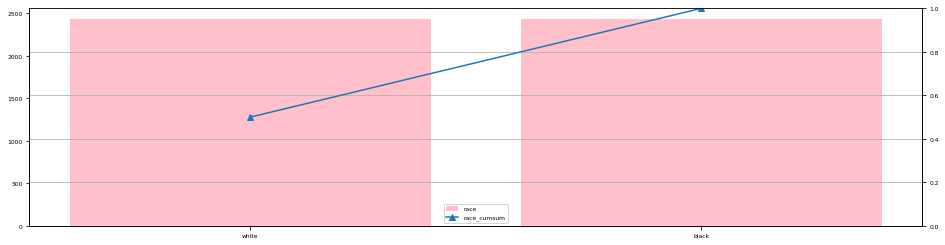
これで各質的データの全体感が掴めたと思います。
まとめ
本記事では、データ分析ではじめに実施するデータ確認の方法を、「社会科学のためのデータ分析」で使用されている米国のオープンデータセットを使ったサンプルコードを交えて紹介しました。
- データをざっくりと理解する方法
- 量的データの基本統計量を確認する方法
- 量的データの分布をヒストグラムで確認する方法
- 質的データの度数分布を確認する方法
- 質的データの度数分布をパレート図で確認する方法
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。