



Pandas では少しの工夫で特徴を捉えるためのデータを出力することが出来ます。
しかし、テキストデータだけではどうもイメージがし辛いと思います。
本記事では、Pandas の DataFrame をインプット情報として plotly で散布図を並べて出力する方法を紹介します。
散布図を並べて出力するサンプルコード(Colab で利用可能)
サンプルデータセット
「社会科学のためのデータ分析」で用いられているオープンデータセットでの使用例を紹介します。
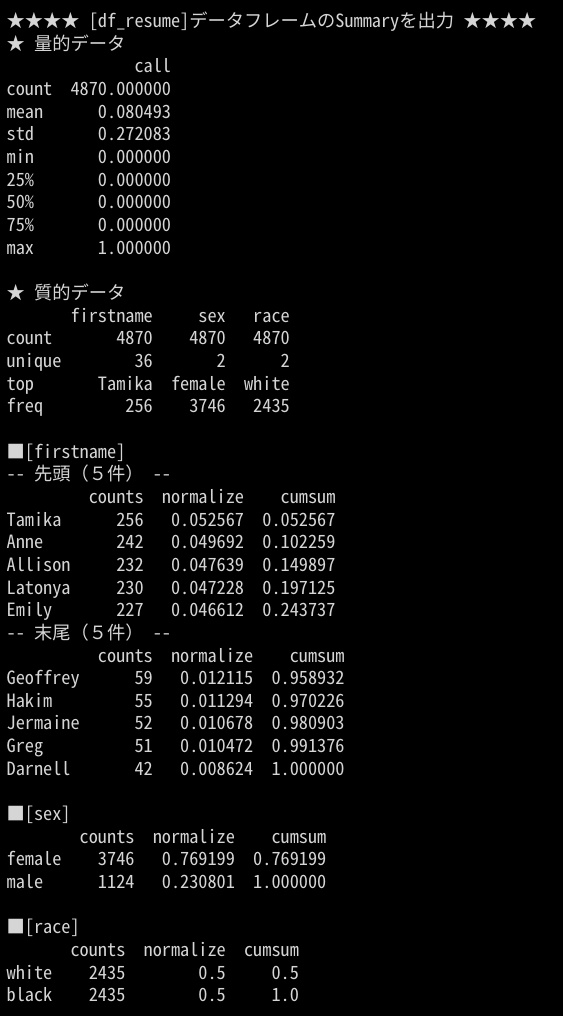
出力イメージ
DataFrame の量的データの散布図を並べて出力することが出来ます。
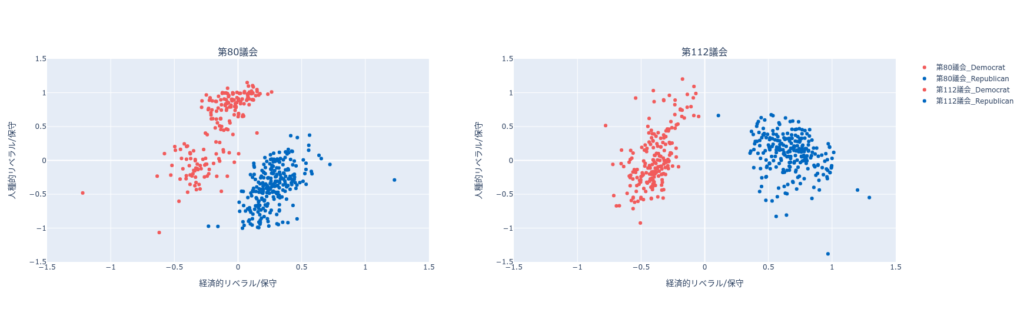
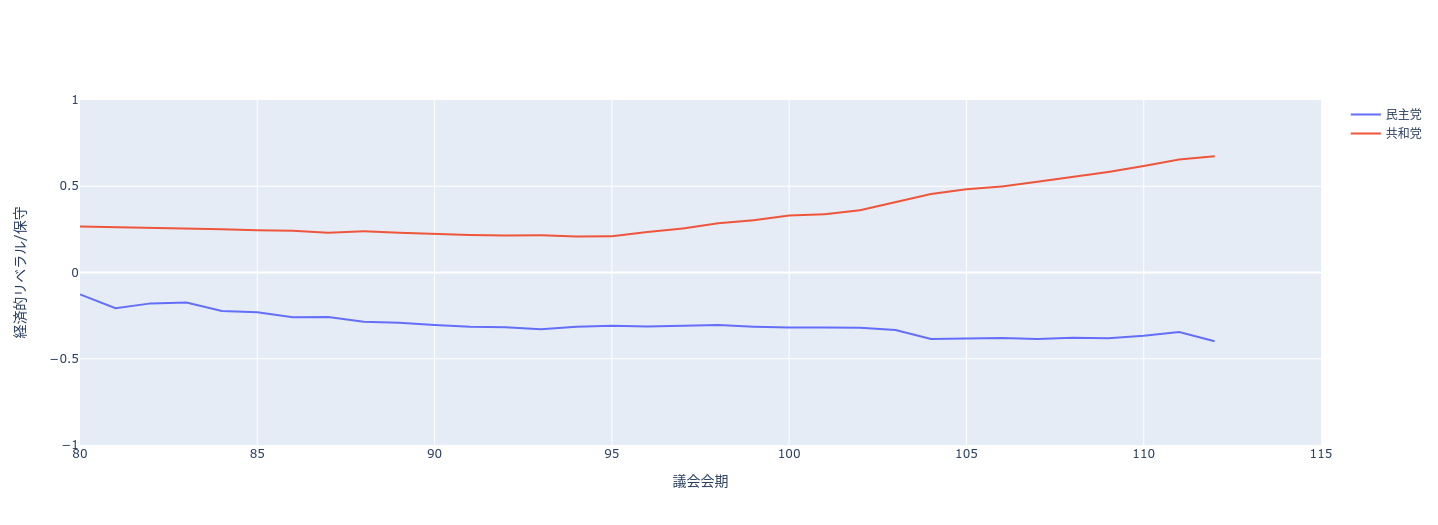
散布図から、第112議会では(第80議会と対比して)民主党と共和党のイデオロギー的な違いを説明する上で、人種的リベラル/保守の次元はもはや重要ではないことがわかる。経済の次元が党派的な違いを主として説明するようであり、それに比べて人種の次元に関する民主党と共和党の違いは目立たない。
「社会科学のためのデータ分析入門(上)」3測定 3.6 「2変量関係の要約」
コード
下記コードを Google Colaboratory のセルにコピペして実行することで直ぐに使えます。
import pandas as pd
from plotly.subplots import make_subplots
import plotly.graph_objects as go
def congress_go_scatter(_df, _congress, _party, _color):
return go.Scatter(
x=_df[(_df["congress"]==_congress) & (_df["party"]==_party)]['dwnom1'],
y=_df[(_df["congress"]==_congress) & (_df["party"]==_party)]['dwnom2'],
mode='markers',
marker_color=_color,
name=f"第{_congress}議会_" + _party
)
df_congress = pd.read_csv('https://raw.githubusercontent.com/kosukeimai/qss/master/MEASUREMENT/congress.csv')
fig = make_subplots(
rows=1,
cols=2,
subplot_titles=("第80議会", "第112議会")
)
fig.add_trace(congress_go_scatter(df_congress, 80, "Democrat", "#F15B5B"), row=1, col=1)
fig.add_trace(congress_go_scatter(df_congress, 80, "Republican", "#0067C0"), row=1, col=1)
fig.add_trace(congress_go_scatter(df_congress, 112, "Democrat", "#F15B5B"), row=1, col=2)
fig.add_trace(congress_go_scatter(df_congress, 112, "Republican", "#0067C0"), row=1, col=2)
fig.update_xaxes(title_text="経済的リベラル/保守", range=[-1.5, 1.5], row=1, col=1)
fig.update_xaxes(title_text="経済的リベラル/保守", range=[-1.5, 1.5], row=1, col=2)
fig.update_yaxes(title_text="人種的リベラル/保守", range=[-1.5, 1.5], row=1, col=1)
fig.update_yaxes(title_text="人種的リベラル/保守", range=[-1.5, 1.5], row=1, col=2)
fig.show()まとめ
本記事では、Pandas の DataFrame をインプット情報として plotly で散布図を並べて出力するメソッドを紹介しました。
データ分析に関して、一つ一つ丁寧に確認したい方は下記記事をご覧ください。
合わせて下記もご参考ください。
ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。