



Pandas の DataFrame はレコードデータを扱うのに大変便利なライブラリですが、データベースにデータを蓄積したりデータを取得したりするメソッドも用意されています。
本記事では、Pandas の Dataframe を SQLite などの DataBase に登録し、さらに SQL を使用して取得したデータを DataFrame に格納する方法を紹介します。スクレイピングや複数の Excel ファイルを読み込んで 蓄積する方法をサンプルコードを交えて紹介します。
目次
全体概要
① データの蓄積:pandas.DataFrame.to_sql() を使用
pandas.DataFrame に用意されている、to_sql() というメソッドを使用すると DataFrame のデータをデータベースに登録することが出来ます。
DataFrame.to_sql(name, con, schema=None, if_exists=’fail’, index=True, index_label=None, chunksize=None, dtype=None, method=None)
pandas.DataFrame.to_sql
② データの取り出し:pandas.read_sql() を使用
pandas に用意されている、read_sql() というメソッドを使用するとデータベースから取得した結果を DataFrame に格納することが出来ます。
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
pandas.read_sql
紹介するサンプルコードの特徴
本記事では、pandas の to_sql() と read_sql() を使用したすぐに使えるサンプルコードを紹介します。リファレンスにもサンプルコードが記載されていますが、応用時の課題として、「SQLite3 に限定した使用方法」であることや「人工的に作成したデータを使用」していること「Colab ではそのままでは使用出来ない」ことから普段 Colab をメインにしている人にはやや扱い辛いです。
この後紹介するサンプルコードのポイントは以下の3つです。
- SQLAlchemy を使用しており SQLite3 以外のデータベースへの応用も容易
※リファレンスのサンプルではSQLite3 に限定しての使用方法 - 外部サイトから収集したデータをデータベースに蓄積する
- Colab で直ぐに実行出来て Google ドライブにデータを蓄積出来る
※データ収集の方法は下記記事で紹介した方法(すべて Colab から利用可能)を参考にしています。
- スクレイピングして table 要素をDataFrameに格納する方法
- Web にアップされている統計データ(Excel)を Google ドライブ に集約する方法
- Google ドライブに格納された複数の Excel ファイルを読み込んで DataFrame に格納する方法
- Colab から SQLite を使用する方法
サンプル① スクレイピングした結果の蓄積と取り出し
サンプルの処理の流れ
- スクレイピングして table 要素を dataframe に格納する
- ①の結果をDataBaseに登録する
- 蓄積したデータの取り出し
- データ登録後 index(SQLite の場合) を追加する
コードがやや長いので本記事には全てを記載しておりません。
Databaseサンプル.ipynb”>![]()
そのままでは実行出来ないので DBセッションの作成
サンプルの処理の流れ コードがやや長いので本記事には全てを記載しておりません。 本記事では、Pandas の Dataframe を SQLite などのデータベースに登録し、さらに SQL を使用して取得したデータを DataFrame に格納する方法を紹介しました。ご参考になりましたら twitter をフォローして SNS でシェアして頂ければ幸いです。 ちなみに今回は下記 Chromebook を使用しました。_colab_dir = "/content/drive/MyDrive/Colab Notebooks/"
db_path = 'sqlite:///' + _colab_dir + 'scraping.sqlite3.db'
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine(db_path)
SessionClass = sessionmaker(engine) # セッションを作るクラスを作成
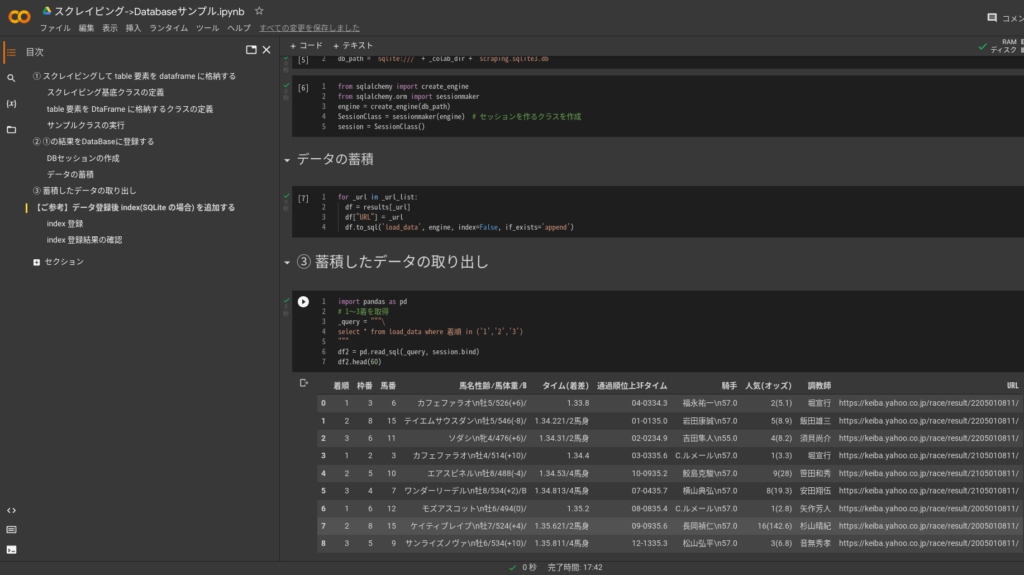
session = SessionClass()データの蓄積
for _url in _url_list:
df = results[_url]
df["URL"] = _url
df.to_sql('load_data', engine, index=False, if_exists='append')蓄積したデータの取り出し
import pandas as pd
# 1〜3着を取得
_query = """\
select * from load_data where 着順 in ('1','2','3')
"""
df2 = pd.read_sql(_query, session.bind)
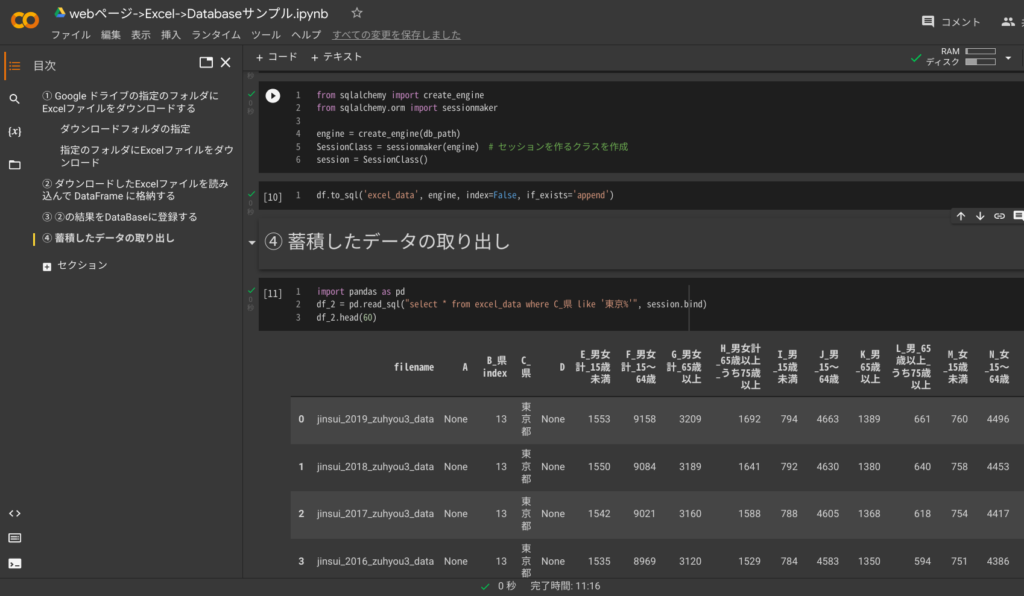
df2.head(60)サンプル② 複数の Excel データの蓄積と取り出し
Excel_>Databaseサンプル.ipynb”>![]()
まとめ
ご参考
14.0型フルHD × Core i3 × メモリ8GB を満たす数少ない端末です。
軽くて持ち運びしやすく開発に耐えうるスペックなのでおすすめです。
 | 価格:70,510円 |