



本記事では、Google Colaboratory から直接実行可能なサンプルコードを用意しています。本記事を最後まで読むと、URL と table 要素を特定するセレクタを入力して table 要素 を DataFrame に格納する方法が解ります。
この手法を身につけるとデータ収集を効率に進めることが出来るようになります。
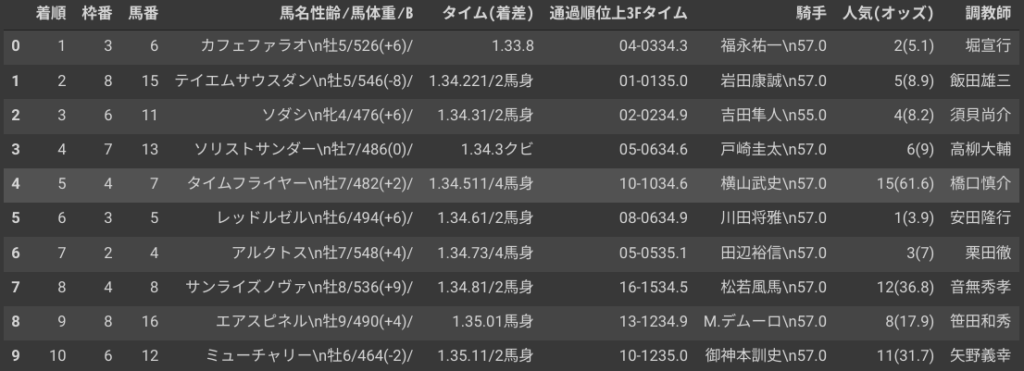
これが↓
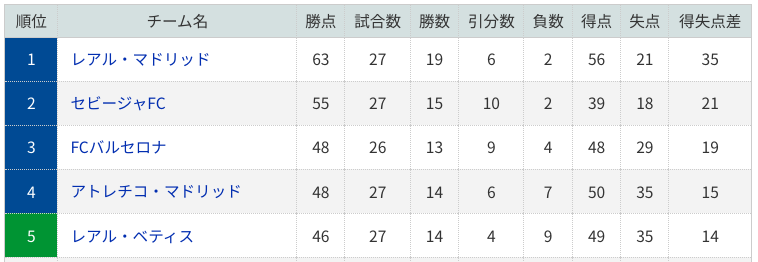
こうなります↓
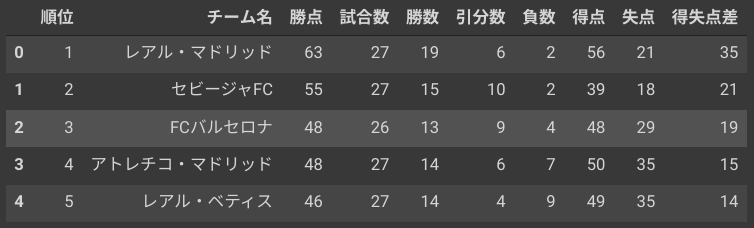
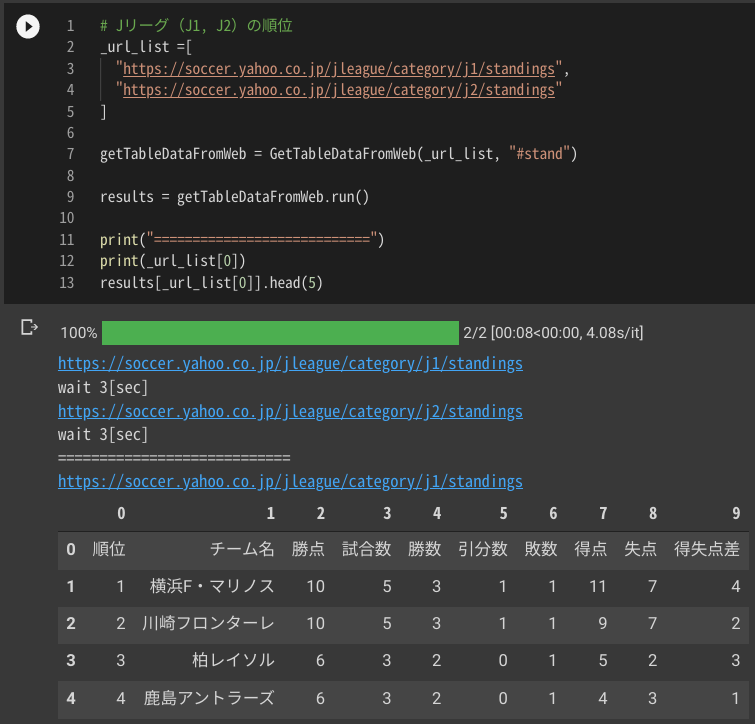
これが↓
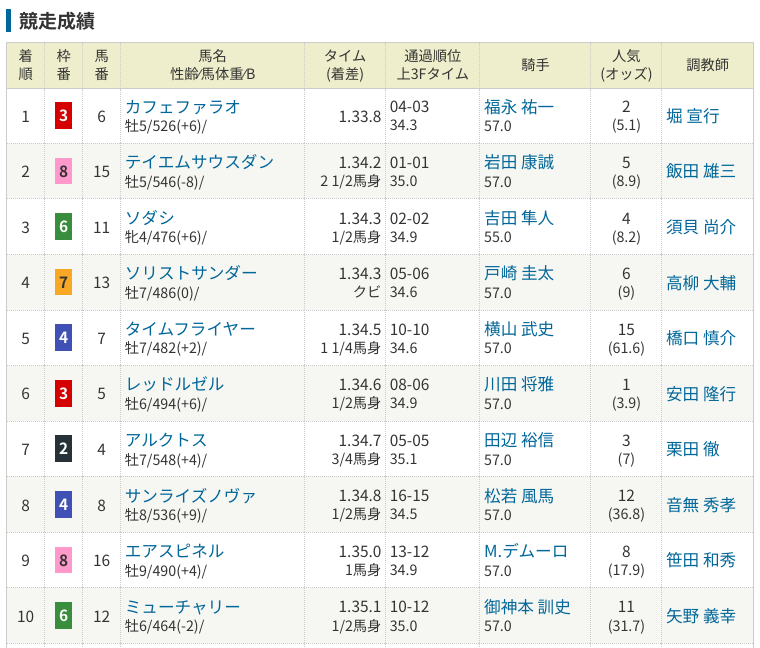
こうなります↓
スクレイピングのサンプルコードを実行する
サンプルコードを Google Colaboratory で起動する
下記をクリックして Colab を起動してください。
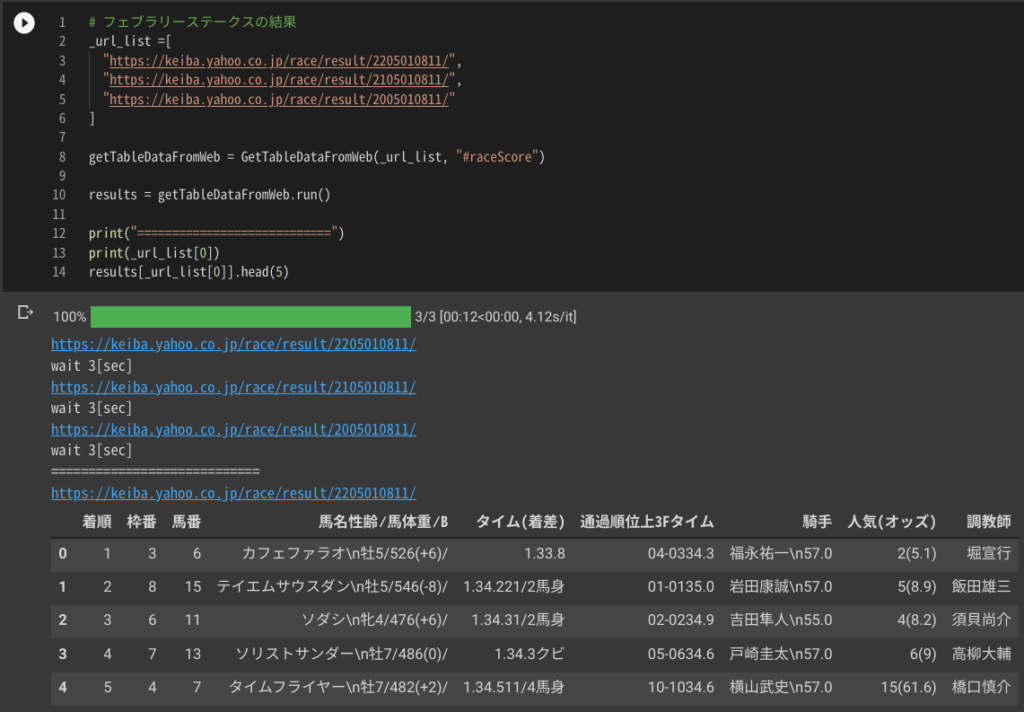
スクレイピングする
まずは試しに実行します。
ツールバーから [ランタイム] _ [すべてのセルを実行] をクリックしてください。

下記が出力されます
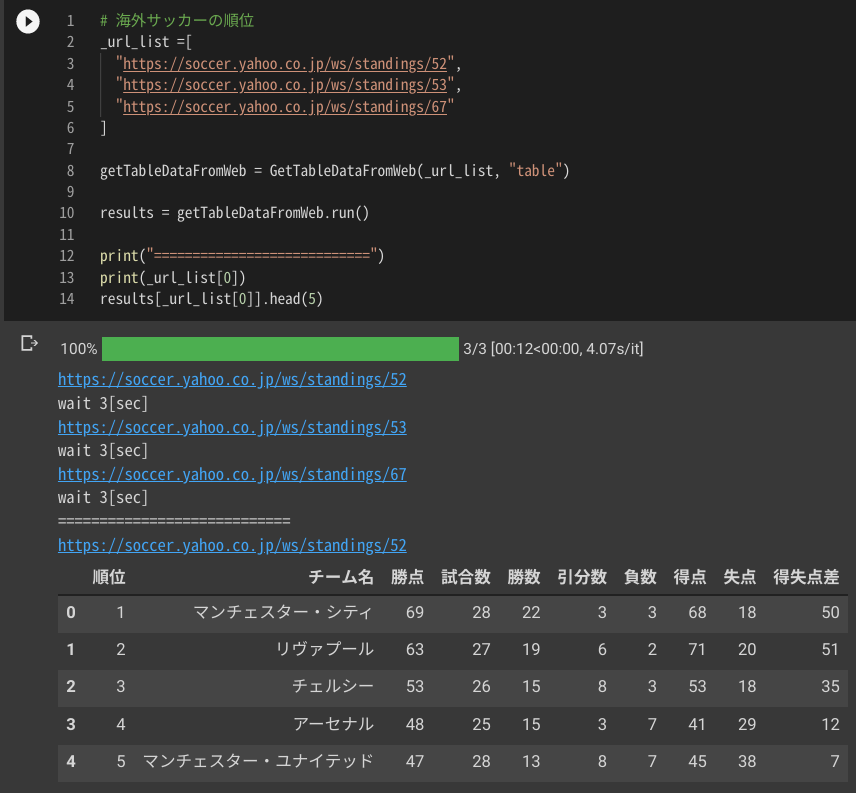
サンプルコード解説
今回のサンプルコードは大きく3つの処理に分かれています。
- スクレイピング基底クラスの定義
- table 要素を DtaFrame に格納するクラスの定義
- サンプルクラスの実行
def htmldoc2data(self, _html_doc):
soup = BeautifulSoup(_html_doc, "html.parser")
# テーブルを取得
_table = soup.select_one(self.__css_selector)
# theadタグを探す
thead = _table.find('thead')
# tbodyタグを探す
tbody = _table.find('tbody')
if thead is not None and tbody is not None:
# パターン①:thead と tbody タグが存在する場合
# ヘッダーを取得
ths = thead.tr.find_all('th')
# DataFrame のヘッダーを作成
columns = []
for th in ths:
columns.append(th.text)
df = pd.DataFrame(columns=columns)
# body を取得
trs = tbody.find_all('tr')
for tr in trs:
# 各レコードからテキストを取得し、空白行や余計な空白を削除してDataFrame に格納して返却
tdlist = []
for td in tr.find_all('td'):
tdlist.append(self.remove_blank_line_and_blank(td.text))
sr = pd.Series(tdlist, index=df.columns)
df = df.append(sr, ignore_index=True)
return df
else:
# パターン②:thead と tbody タグのいずれかが存在しない場合
df = pd.DataFrame()
trs = _table.find_all('tr')
for tr in trs:
# 各レコードからテキストを取得し、空白行や余計な空白を削除してDataFrame に格納して返却
tdlist = []
for td in tr.find_all('th'):
tdlist.append(self.remove_blank_line_and_blank(td.text))
for td in tr.find_all('td'):
tdlist.append(self.remove_blank_line_and_blank(td.text))
if len(tdlist) > 0:
sr = pd.Series(tdlist)
df = df.append(sr, ignore_index=True)
return dfサンプルコードの使用方法
GetTableDataFromWeb クラスの第一引数にURLのリスト、第二引数にセレクタを指定することでtable要素をDataFrameに格納することが出来ます。
# フェブラリーステークスの結果
_url_list =[
"https://keiba.yahoo.co.jp/race/result/2205010811/",
"https://keiba.yahoo.co.jp/race/result/2105010811/",
"https://keiba.yahoo.co.jp/race/result/2005010811/"
]
getTableDataFromWeb = GetTableDataFromWeb(_url_list, "#raceScore")
results = getTableDataFromWeb.run()
print("============================")
print(_url_list[0])
results[_url_list[0]].head(5)セレクタについては、各ブラウザのデベロッパーツールなどを使用して対象の web ページの html を参照して確認してください。デベロッパーツールを起動して各タグにマウスを重ねると対応する箇所が薄い水色でハイライトされるので、割と簡単に見つけられます。
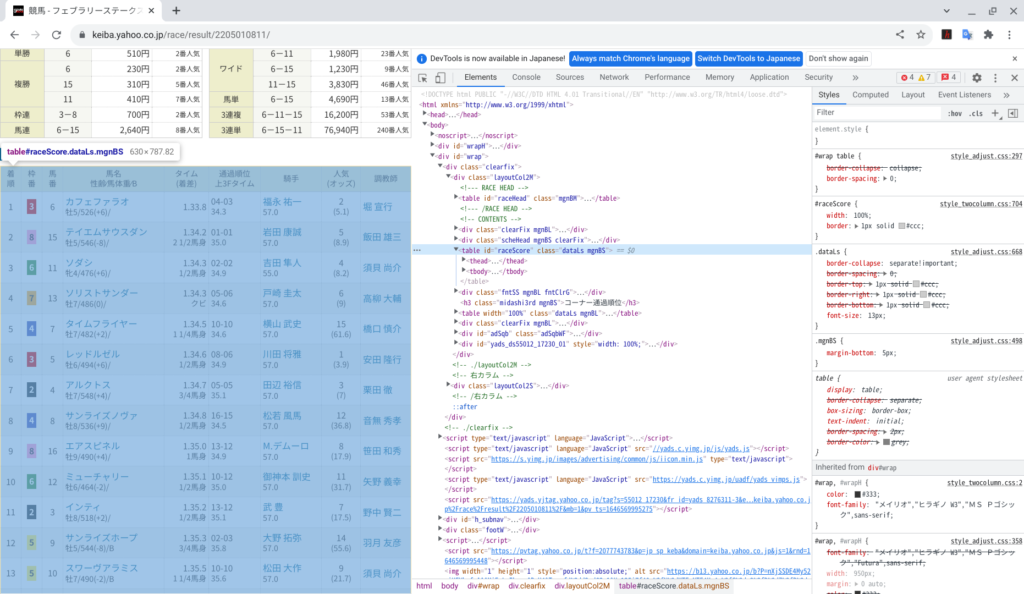
テーブルに対応するタグが下記であることが解ります。ここから、セレクタが “#raceScore” であることが解ります。

おわりに
本記事では、スクレイピングして html の table 要素 を Dataframe に格納するサンプルコードを紹介しました。ご参考になりましたら twitter をフォローしてSNSでシェアして頂ければ幸いです。