



データ分析に挑戦しているけどデータ準備の負荷が高くて途中で挫折してませんか?
本記事では、Google Colaboratory を使用して Google ドライブの複数の Excel ファイルを DataFrame に格納して plotly で可視化する方法を紹介します。
本記事のポイントは3つです。
目次
【準備】Excel ファイルをGoogleドライブに格納する
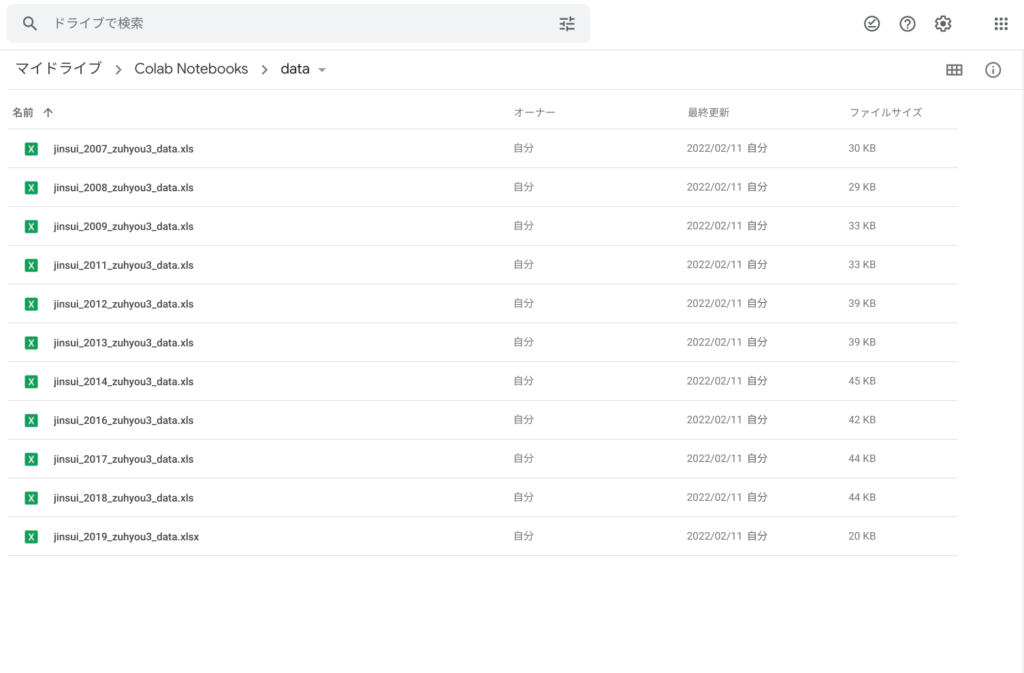
Google ドライブの “Colab Notebooks” フォルダ配下に “data” フォルダを作成します。
web にアップされている統計データなどの Excel ファイルを格納します。(.xls, .xlsxの混在可)
Excel データを DataFrame に格納する
Google ドライブの Excel ファイルを DataFrame に格納する方法を説明します。
ここでは、可視化時の操作を容易にするために縦持ちで格納します。
Google ドライブをマウントする
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')xlrd をインストールする
! pip install xlrd==2.0.0Excel ファイルのフルパスリストを作成する
filelistInGoogleDrive = [
"jinsui_2019_zuhyou3_data.xlsx",
"jinsui_2018_zuhyou3_data.xls",
"jinsui_2017_zuhyou3_data.xls",
"jinsui_2016_zuhyou3_data.xls",
"jinsui_2014_zuhyou3_data.xls",
"jinsui_2013_zuhyou3_data.xls",
"jinsui_2012_zuhyou3_data.xls",
"jinsui_2011_zuhyou3_data.xls",
"jinsui_2009_zuhyou3_data.xls",
"jinsui_2008_zuhyou3_data.xls",
"jinsui_2007_zuhyou3_data.xls"
]
_basepath = r"/content/drive/MyDrive/Colab Notebooks/data/"
filepathlistInGoogleDrive = []
for filename in filelistInGoogleDrive:
filefullpath = _basepath + filename
filepathlistInGoogleDrive.append(filefullpath)Excel ファイルを読み込む
# ダウンロードしたExcelファイルの読み込み
import os
import pandas as pd
dfs = {}
# カラム名を指定
colnames=[
"A",
"B_県index",
"C_県",
"D",
"E_男女計_15歳未満",
"F_男女計_15~64歳",
"G_男女計_65歳以上",
"H_男女計_65歳以上_うち75歳以上",
"I_男_15歳未満",
"J_男_15~64歳",
"K_男_65歳以上",
"L_男_65歳以上_うち75歳以上",
"M_女_15歳未満",
"N_女_15~64歳",
"O_女_65歳以上",
"P_女_65歳以上_うち75歳以上"
]
i=0
for _path in filepathlistInGoogleDrive:
print(_path)
# 14行目から読み込む
skip_rows = range(0,13)
_filename, ext = os.path.splitext(os.path.basename(_path))
df_temp = pd.read_excel(_path, header=None, skiprows=skip_rows, names=colnames)
# 一番左に列を追加しファイル名を格納
df_temp.insert(0, 'filename', _filename)
# "C:県"に格納されている値にtrimを実施
# ※桁数を揃えるために空白が格納されているため
df_temp["C_県"] = df_temp["C_県"].str.strip()
# 1つのDataFrameに集約
if i==0:
df = df_temp
else:
df = pd.concat([df, df_temp])
i+=1DataFrame を可視化する(サンプルコードあり)
DataFrame に読み込んだデータを可視化する方法を説明します。
縦持ちでのデータを可視化していますので、属性毎(例えば県毎など)に色分けをするのが簡単です。
import plotly.express as px
from plotly.offline import iplot, plot, download_plotlyjs, init_notebook_mode
import plotly.graph_objs as go
# ファイル名から年度を取得
df["year"]=df["filename"].str.replace("jinsui_","")
df["year"]=df["year"].str.replace("_zuhyou3_data","")
df["year"]=df["year"].astype(int)
# 全人口における15~64歳の割合を算出
df["wariai"]=df["F_男女計_15~64歳"]/(df["E_男女計_15歳未満"]+df["F_男女計_15~64歳"]+df["G_男女計_65歳以上"])
# 三重県、奈良県、福岡県、東京都のみ抽出
df2 = df[df['C:県'].isin(["三重県","奈良県","福岡県","東京都"])]
# 可視化
fig = px.line(df2, x="year", y="wariai", color='C:県',log_y=False)
fig.show()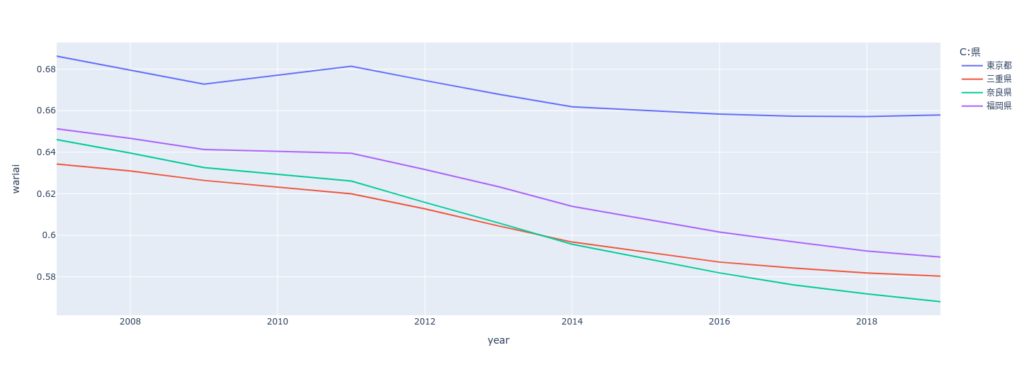
全人口に占める14歳〜64歳の割合は、東京は他県と比較して横ばいであることが解ります。
おわりに
本記事では、xlxとxlsxが混在する複数の Excel ファイルを DataFrame に縦持ちで格納する方法を紹介しました。ご参考になりましたらtwitterをフォローしてSNSでシェアして頂ければ幸いです。
オープンデータセットを使ったデータ分析も用意しておりますのでご参考いただければと思います。
ご参考
ちなみに今回は下記 Chromebook を使用しました。
14.0型フルHD × Core i3 × メモリ8GB を満たす数少ない端末です。
軽くて持ち運びしやすく開発に耐えうるスペックなのでおすすめです。
 | 価格:70,510円 |
ちなみに、Chromebook でプログラミングを始める方法についてもご参考ください。