



目次
こんなお困りごとないですか?

大学生
最近は気象データやコロナに関するオープンデータがネット上で簡単に取得可能だけど、csv形式のデータだけでは得られる知見が無い。
何か加工してデータから情報を得たいな。
だけど方法が解らない。
※本記事はChrombookを使用して執筆しました
解決方法は?
あるよ。

忠犬SE
Pandasというフレームワークを使えば、csvファイルの操作が簡単に行えるよ。複数のファイルを条件に合わせて抽出したり結合したりできるよ。
また、Plotlyというフレームワークを使えば簡単に可視化出来るよ。
つまり、Google Colaboratoryを使えばすぐに可視化出来るよ。
忠犬SE
複数のcsvファイルを整形して可視化する方法
流れ
- 全体概要を理解する
- csvファイルを用意する
- Colabのノートブックを作成する
- 実際に動かしてみる
- STEP
全体概要を理解する
- Google ドライブにcsvファイルを格納する
- Pandasを使用してcsvファイルを読み込みデータフレームに格納する
この時点では、データフレームはcsvファイル毎に作成する - データフレームを加工する
- カラム名をリネームする
- データフレームを横に結合する
- データフレームを縦に結合する
- データフレームに新たな列を追加し計算した値を格納する
- Plotlyを使用してデータフレームを可視化する
- 統計情報を可視化する
- アニメーションのあるグラフを表示する
- 複数グラフを並べて表示する
- STEP
csvファイルを用意する
過去の気象データを取得する
下記サイトから気象データをCSVダウンロードして、加工します。
東京・大阪・北海道の2021/1/1-2021/9/1の1日あたりの平均気温と平均室温のデータを用意しました。
pandasによる加工を容易にするためcsvファイルの時点で一部加工している。加工前のデータについては実際にサイトからデータをダウンロードしてご確認頂きたい。
新型コロナウイルス感染症情報を取得する
下記サイトから新型コロナウイルスの感染症情報をダウンロードします。
新規陽性者数の推移(日別)
人口10万人当たり新規陽性者数
重症者数の推移
のオープンデータをクリックすることでダウンロードできます。
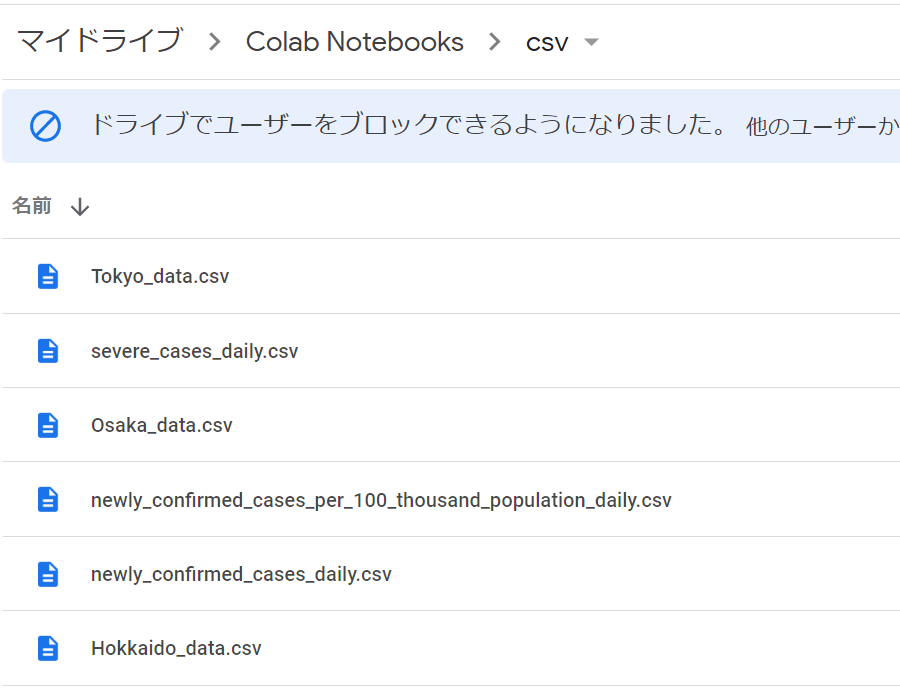
Google ドライブにアップロードします
Google ドライブのColba Notebooksフォルダの配下にcsvフォルダを作成し、先ほど用意したcsvファイルをアップロードします。
- STEP
Colabのノートブックを作成する
下記記事などを参考に、Colabで新しいノートブックを作成します。
- STEP
実際に動かしてみる
下記流れで実行します。
1. Google ドライブのマウント
下記コードをコピーして実行してGoogle ドライブをマウントします。
# Googleドライブのマウント from google.colab import drive drive.mount('/content/drive')2. csvファイルの読み込みデータフレームに格納
ここでは、pandasパッケージのread_csvという関数を使用します。
Google ドライブをマウント後、下記コードを実行してcsvファイルを読み込みデータフレームに格納します。
import pandas as pd df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/newly_confirmed_cases_daily.csv") df_100 = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/newly_confirmed_cases_per_100_thousand_population_daily.csv") df_severe_cases_daily = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/severe_cases_daily.csv") df_Tokyo_data = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/Tokyo_data.csv") df_Hokkaido_data = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/Hokkaido_data.csv") df_Osaka_data = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/csv/Osaka_data.csv")3. データフレームの加工
csvファイルをそのまま読み込んだだけでは可視化出来ないので、データフレームを加工します。
3-1. カラム名のリネーム
データフレームのカラム名のリネームにはrenameというメソッドを使用します。
下記コードを実行してカラム名をリネームします。
# カラム名が長いのでリネーム df_100 = df_100.rename(columns={"Newly confirmed cases (per 100,000 population)":"Newly confirmed cases(100)"})3-2. 横に結合
データフレームを横に結合するには、pandasパッケージのmergeという関数を使用します。
下記コードを実行してデータフレームを横に結合します。
ここでは、東京・大阪・北海道のそれぞれの平均気温と湿度のデータフレームに対しコロナウイルスの感染症情報を横に結合しています。各csvファイルは、DateカラムとPrefectureカラムを共通で保持しており、両カラムが等しいレコードを横に結合しています。
# 横に結合 # 東京 df_new_Tokyo = pd.merge(df_Tokyo_data,df, on=["Date","Prefecture"]) df_new_Tokyo = pd.merge(df_new_Tokyo,df_100, on=["Date","Prefecture"]) df_new_Tokyo = pd.merge(df_new_Tokyo,df_severe_cases_daily, on=["Date","Prefecture"]) df_new_Tokyo.head() # 大阪 df_new_Osaka_data = pd.merge(df_Osaka_data,df, on=["Date","Prefecture"]) df_new_Osaka_data = pd.merge(df_new_Osaka_data,df_100, on=["Date","Prefecture"]) df_new_Osaka_data = pd.merge(df_new_Osaka_data,df_severe_cases_daily, on=["Date","Prefecture"]) df_new_Osaka_data.head() # 北海道 df_new_Hokkaido_data = pd.merge(df_Hokkaido_data,df, on=["Date","Prefecture"]) df_new_Hokkaido_data = pd.merge(df_new_Hokkaido_data,df_100, on=["Date","Prefecture"]) df_new_Hokkaido_data = pd.merge(df_new_Hokkaido_data,df_severe_cases_daily, on=["Date","Prefecture"]) df_new_Hokkaido_data.head()3-3. 縦に結合
データフレームを縦に結合するにはpandasパッケージのconcatという関数を使用します。
下記コードを実行してデータフレームを縦に結合します。
ここでは、各データフレームのカラムが同一なのでそのまま縦方向にデータが追加されます。
# データフレームを立てに結合 df_new = pd.concat([df_new_Tokyo, df_new_Hokkaido_data, df_new_Osaka_data])3-4. データフレームに新たな列を追加し計算した値を格納
下記コードを実行して、日単位の不快指数を計算します。
ここでは、新たにhukaiというカラムを追加し、そこに計算結果を格納しています。
# 不快指数を計算。 df_new["hukai"]=0.81*df_new["kion"]+0.01*df_new["situdo"]*(0.99**df_new["kion"]-14.3)+46.3また、可視化パラメータを指定するようにsizeというカラムを追加して数値の2を格納します。
# 可視パラメータ df_new["size"]=2- 4. Plotlyを使用してデータフレームを可視化する
4-1. データフレームに格納されている値の統計情報を可視化する
下記コードを使用して、データフレームに格納されている統計情報を可視化します。
df_new.describe()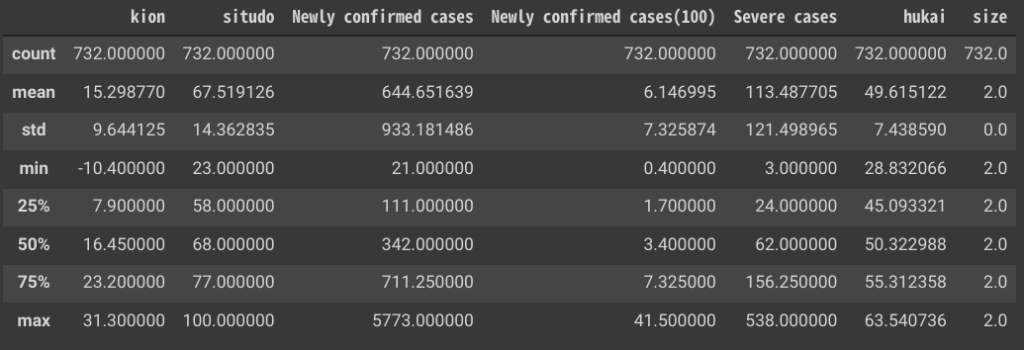
4-2. Plotlyを使用してデータフレームを可視化する(アニメーション)
下記コードを使用して、データフレーム可視化します。
ここではアニメーションを指定しており、日ごとのデータでアニメーションをします。
import plotly.express as px animation_fig = px.scatter( df_new, x="hukai", range_x=[20, 70], # hukaiの最小と最大が含まれるように指定 y="Newly confirmed cases(100)", range_y=[0, 50], # Newly confirmed cases(100)の最小と最大が含まれるように指定 log_x=True, size="size", size_max=40, color="Prefecture", width=800, animation_frame="Date", # 日ごとのデータでアニメーション ) animation_fig.update_xaxes(tickfont={"size": 8}) animation_fig.show()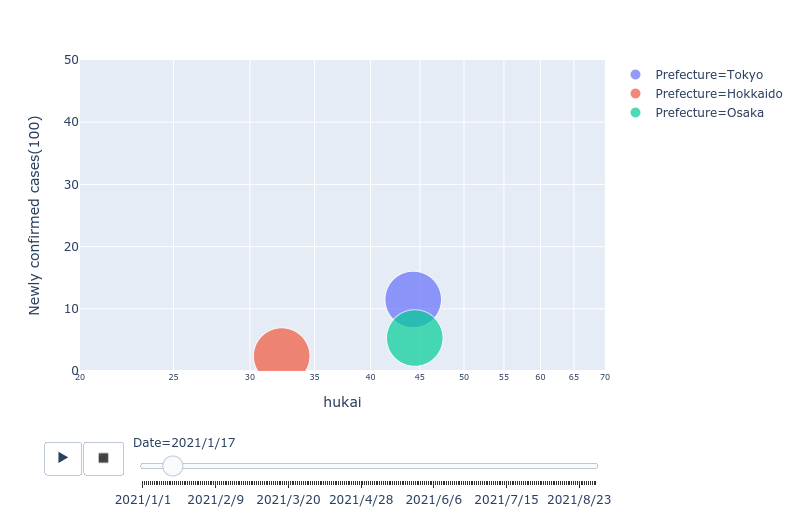
4-3. Plotlyを使用してデータフレームを可視化する(複数グラフ)
下記コードを実行して、関数を定義します。
ここでは、複数のグラフを立てに並べて可視化するグラフを定義しています。
import plotly.graph_objects as go from plotly.subplots import make_subplots def draw_subplot(p_df, p_prefecture_list, p_days, p_draw_data_list): _fig = make_subplots(rows=len(p_draw_data_list), cols=1, subplot_titles=tuple(p_draw_data_list)) _col_idx = 0 for p_draw_data in p_draw_data_list: _col_idx += 1 for p_Prefecture in p_prefecture_list: # データ抽出 _df = p_df[p_df["Prefecture"] == p_Prefecture] # 移動平均 _df.loc[:, p_draw_data] = _df.rolling(p_days).mean() _fig.add_trace(go.Scatter(x=_df["Date"], y=_df[p_draw_data], name=p_Prefecture), row=_col_idx, col=1) _fig['layout'].update(height=300*_col_idx) _fig.show()下記コードを実行してグラフを描画します。
draw_subplot(df_new, ["Tokyo","Hokkaido","Osaka"], 7, ["hukai", "Newly confirmed cases","Severe cases"])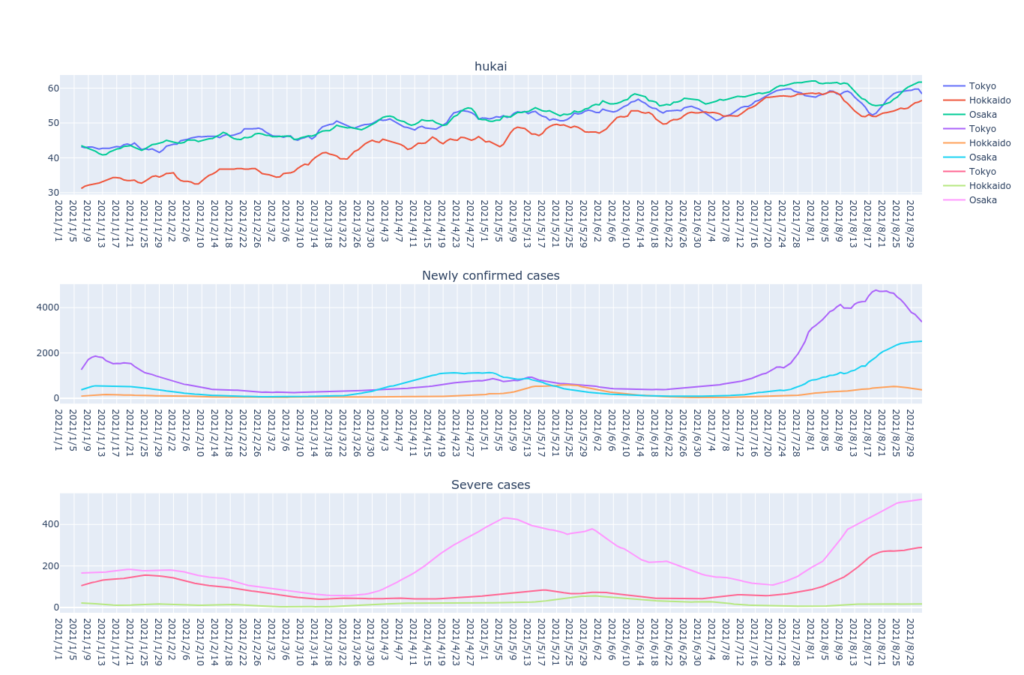
最後に
本日は、複数のCSVファイルを整形してグラフに表示してみました。ご参考になりましたらtwitterをフォローしてSNSでシェアして頂ければ幸いです。
さらに、理解を深めたいというかたは、↓も見てね。
忠犬SE
【付録】さらに理解を深めたいという方たちへ①
理解を深めるためには、実際に動かしてみるのが一番です。
下記テーマを参考に、色々と動かしてみてはいかがでしょうか?
- 14日移動平均のグラフを作成する
- 愛知県をグラフに追加する
- 2020/4~2021/9のグラフを作成する
【付録】さらに理解を深めたいという方たちへ②
- 今回はデータの前処理を行っていいます。データ処理の基礎については下記がおすすめです。
- データの前処理にPandasを使用しています。Pandasについて理解を深めたい方には下記がおすすめです。
- 今回可視化で使用したPlotlyへの理解を深める方には下記がおすすめです。
- 今回はデータの可視化止まりでしたが、可視化のその先に興味がある方には下記がおすすめです。
Next Step
ご参考
ちなみに今回は下記 Chromebook を使用しました。
14.0型フルHD × Core i3 × メモリ8GB を満たす数少ない端末です。
軽くて持ち運びしやすく開発に耐えうるスペックなのでおすすめです。
 | 価格:70,510円 |
Chromebook でプログラミングを始める方法については下記記事をご参考下さい。